本文介紹了列存索引行列融合基礎組件(優化器代價模型、執行器多引擎訪問、存儲引擎日志回放和事務處理)以及處理長尾請求問題的HybridIndexSearch算子的相關內容。
背景信息
事務處理(OLTP)和分析處理(OLAP)混合工作負載在當前的業務系統中變得越來越常見。由于有實時、易運維等需求,一些業務系統會采用HTAP數據庫來代替原有的OLTP-ETL-OLAP架構。HTAP數據庫可以在一套數據庫系統中同時較為高效地處理TP請求和AP請求。然而,由于TP請求和AP請求的訪問模式截然不同,高效處理這兩種請求依賴于不同的存儲格式和計算模式。因此,HTAP數據庫需要存儲兩種不同格式的數據,并在處理不同的請求時選擇不同的模式對相應數據進行計算。

云原生數據庫PolarDB采用了上圖中的方式來處理混合型的工作負載。開啟列存索引(In-Memory Column Index,以下簡稱IMCI)功能后,只讀節點(RO)會額外維護一份列式索引,并在處理AP請求時采用向量化的方式對列式數據進行計算(列式計算)。而在處理TP請求時依然采用MySQL原有的one-tuple-at-a-time的方式對行式索引的InnoDB數據進行計算(行式計算)。列式索引和行式索引都通過物理復制鏈路回放讀寫節點(RW)的寫入。在這套系統中,處理兩種請求的存儲、執行器、優化器都彼此獨立,TP請求和AP請求在執行路徑上完全分離,一條SQL語句要么選擇列式計算,要么選擇行式計算。
長尾請求問題
從用戶的工作負載中可以看到,對于混合負載中的大部分請求,“行列分離”的計算方式已經能夠以最優的計劃執行。然而,對于少部分請求,列式計算和行式計算都不是最優的,具體體現在以下幾個方面:
在查詢大寬表時,若對少數列通過WHERE或JOIN條件進行過濾,或查詢TOP K,最后輸出篩選出來的行的所有詳細信息。對于這類查詢,使用列存索引進行查詢的效果較好。但在使用列存索引查詢篩選出的列的詳細信息時,project需要獲取所有的列信息,列存索引在獲取所有的列信息時存在讀放大問題。這種情況下,通過行式索引來查詢詳細信息效果較好。
執行計劃的一個片段是兩張大表
join(t1 join t2),t1表上WHERE條件的過濾比例很高,且有InnoDB索引。t2表上的join條件沒有InnoDB索引且join條件只涉及少數列。在這樣的查詢中,通過行式計算和InnoDB索引查詢t1表,再通過列式計算掃描t2表進行hash join效果較好。以2中的場景為例,t2表上的join條件有InnoDB索引,此時
t1 join t2這個執行片段通過純行式計算進行index join效果較好。執行計劃的其余片段可能通過列式計算的方式執行。
為了更高效地處理混合負載中的這部分長尾請求,在IMCI的優化器和執行器中,基于兩個不同的索引,設計并實現了“行列融合”執行架構。
主要挑戰
在一個“行列分離”的系統中實現“行列融合”,主要的挑戰來自以下幾個方面:
優化器代價估計:MySQL優化器和IMCI優化器的代價模型不同,如果直接以MySQL的代價模型計算行式執行片段的代價,再加上以IMCI的代價模型計算列式執行片段的代價,并不能得到整個執行計劃的代價。需要設置統一的CPU和IO代價單位,再根據行列計算的不同算法復雜度和行列索引不同的統計信息計算出最終的代價。
執行器訪問不同索引:一套執行器需要同時訪問InnoDB和列式索引。MySQL執行器是以單線程的模式執行一個SQL請求,同時也是使用單線程訪問InnoDB相關的接口和上下文。而IMCI執行器是以單leader+多worker的模式處理一個SQL請求。因此,如果在worker中訪問InnoDB就需要進行一些額外的處理。
行列索引實現強一致讀:列式索引和InnoDB回放RW寫入的過程是異步的,兩個不同索引的回放redo log的位點可能不一致。并且InnoDB通過基于LSN的read view判斷數據可見性,而列式索引通過類似LSM存儲引擎的sequence判斷數據可見性。在異步回放下,行列索引只能實現最終一致讀,而“行列融合”的行式執行片段和列式執行片段的可見數據不一致會導致執行結果錯誤。
行列融合基礎組件
優化器的代價模型
長尾請求問題中的三種類型在“行列分離”的執行架構下會基于代價被視為AP請求由IMCI執行。因此,選擇基于IMCI的優化器并引入對行式執行片段的代價估計,從而使這些長尾請求能夠選擇“行列融合”執行計劃。
在引入行式執行代價估計的過程中,需要遵循如下原則:
對于一個執行片段,相對高估其使用行式執行的代價,低估其使用列式執行的代價。因為長尾請求原本會選擇純列式執行,這樣的代價估計可以保證當一個長尾請求選擇“行列融合”的執行計劃時,一定不會比原本的執行計劃更差。
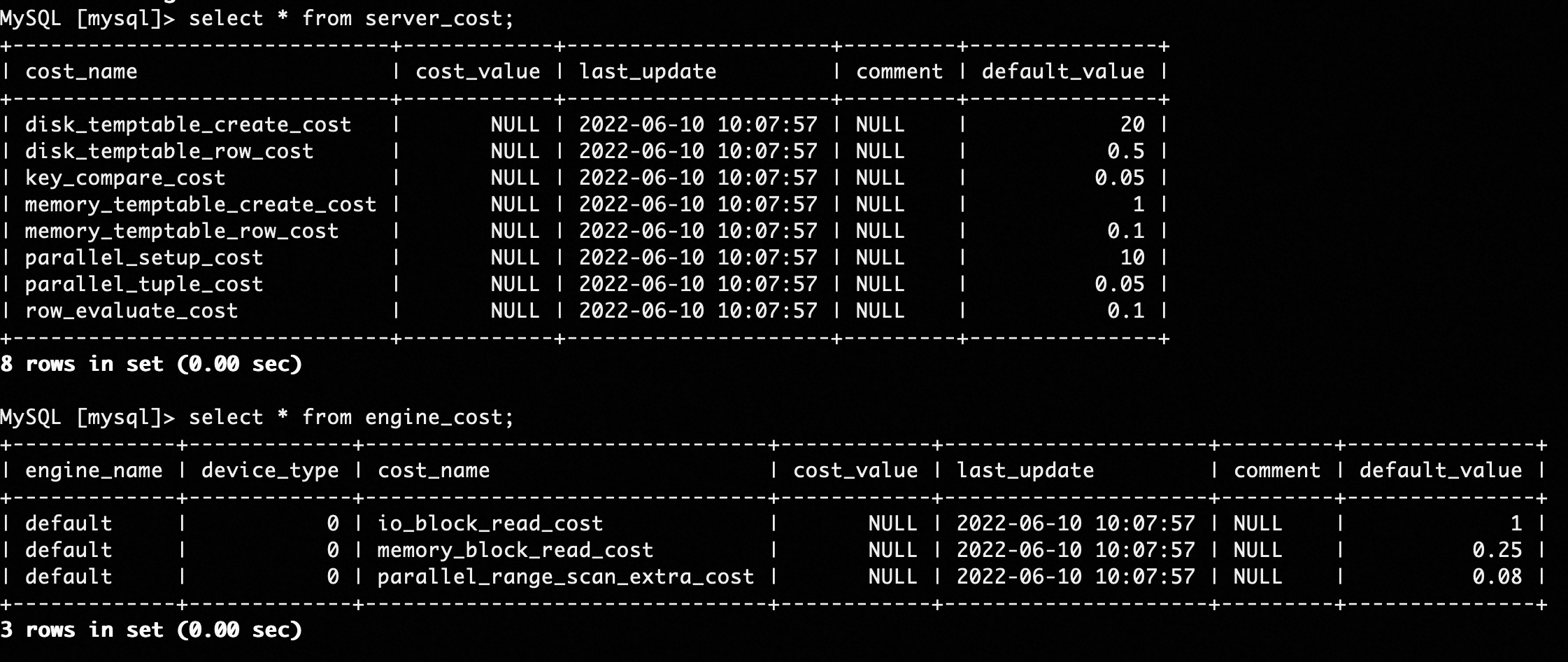
只參考MySQL優化器的代價常量之間的比例。MySQL優化器的代價常量如上圖所示,和IMCI的代價常量具有不同的數量級,因此無法直接使用它們的絕對值,但可以參考它們之間的比例關系。
基于上述原則,IMCI采用如下設計:
在IMCI優化器中,InnoDB的io_block_read_cost和列式索引的pack io cost相同。雖然InnoDB一個page是16 KB,而列式索引的pack是65536行,比16 KB更大,但基于第一個原則,且考慮PolarFS并發下發請求和條帶打散粒度,故設置相同的IO代價常量。
基于第二個原則,memory_block_read_cost和row_evaluate_cost保持相同的比例。
根據上述的代價常量,基于MySQL和IMCI各自的算法和統計信息計算出“行列融合”執行計劃的代價。
執行器的多引擎訪問
IMCI優化器對長尾請求選擇“行列融合”執行計劃后,通過在IMCI執行器中引入新的Hybrid算子來計算行式執行片段。

新的Hybrid算子需要在IMCI執行器中訪問InnoDB,參考MySQL的Server層的實現原理,通過TABLE對象中的handler來和存儲引擎交互。從上圖的執行流程可以看出,雖然Prepare階段已經Open Table,但相關對象和接口都是面向MySQL單線程執行實現的,因此在IMCI執行器的worker中,需要再次Open Table,并克隆或引用相關對象。
存儲引擎的日志回放和事務處理
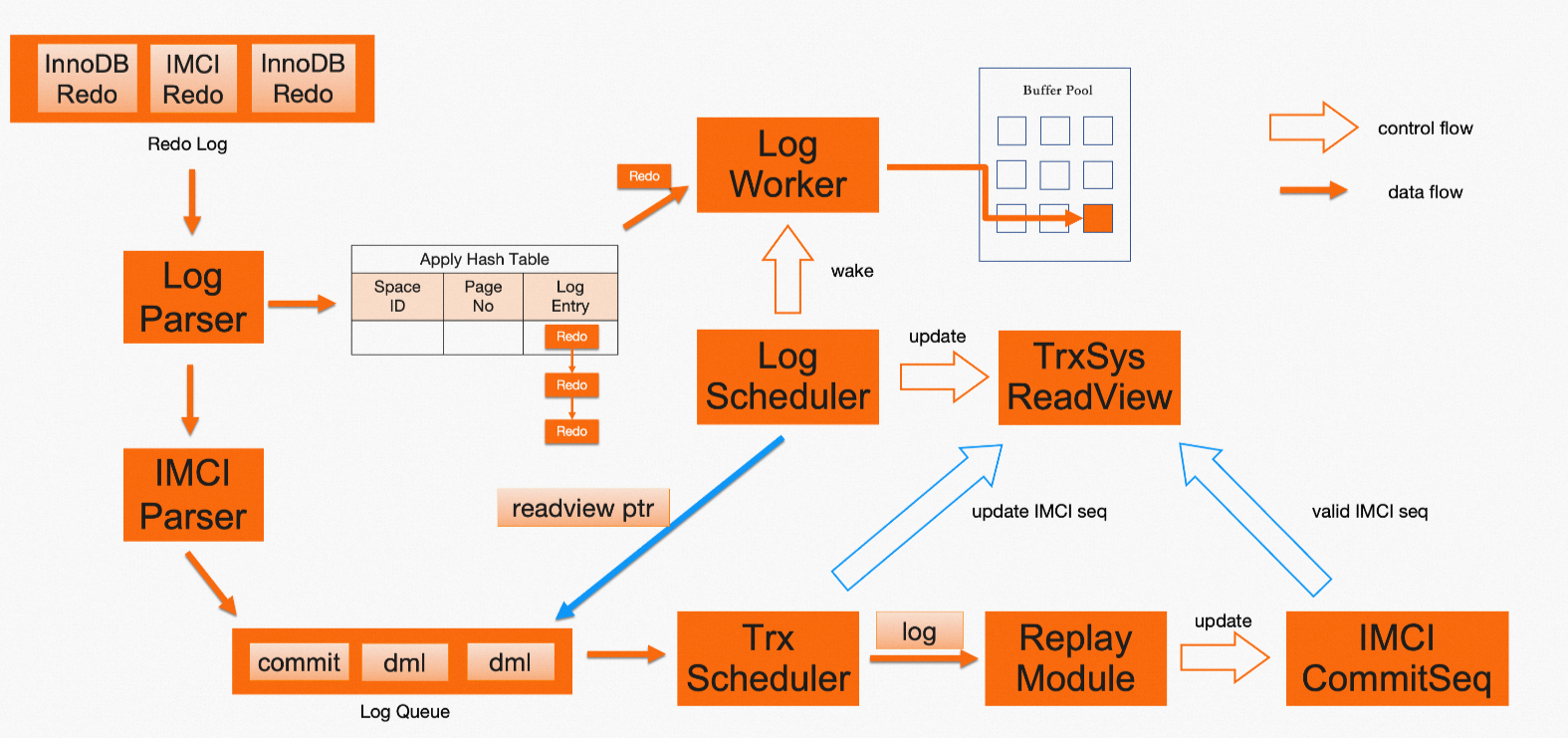
兩個不同索引異步回放的流程如上圖橙色部分所示,其中InnoDB在回放完成后會更新latest read view,而列式索引在回放完成后會更新列式索引的last commit seq。回放流程在接收一定量的redo后運行一次(包含若干條redo log entry),redo內InnoDB事務和IMCI事務的提交情況一致。因此,一段redo在兩個不同索引上都回放完成后,基于更新的latest read view和last commit seq,兩個不同索引上的數據可見性保持一致,上述read view和commit seq稱之為“對應的”。如果查詢使用“對應的”read view和commit seq來判斷數據可見性,就能實現強一致讀。
然而,行列索引的回放流程是異步的,由于回放速度的差異,任意時刻latest read view和last commit seq可能不是“對應的”,這種情況下需要找到最近更新的“對應的”read view和commit seq。為此,在異步回放流程中引入上圖中的藍色部分,流程如下:
對于一段redo,InnoDB在更新latest read view后,會在列式索引的Log Queue中添加一個包含當前latest read view的dummy日志對象。
列式索引單線程順序處理Log Queue,先推送常規日志對象到回放模塊,并計算該次回放完成后更新的commit seq。接下來處理dummy日志對象,將該commit seq設置到對應的read view上。
說明由于在處理dummy日志對象時,之前的常規日志對象可能還沒全部完成回放,因此設置到read view上的commit seq在列式索引上可能尚未生效,回放完成后,這個“對應的”read view和commit seq才可以被使用。
引入該流程后,“行列融合”查詢會在尚未被purge的read view中,尋找一個“對應的”commit seq已經生效的read view來判斷數據的可見性。
HybridIndexSearch
基于行列融合基礎組件,引入了HybridIndexSearch來處理第一種長尾請求問題。HybridIndexSearch通過primary key從InnoDB的主索引獲取完整的行,進行相關表達式的計算后輸出。除了基礎組件提供的能力外,HybridIndexSearch需要執行計劃中它的子算子輸出primary key數據,可以通過優化器搜索執行計劃時,設置primary key的property來實現。
性能測試
該測試基于ClickHouse官方提供的OnTime數據集來驗證“行列融合”執行架構和HybridIndexSearch算子的性能。
OnTime數據集中的表包含110列,是一個典型的大寬表。通過如下SQL語句模擬第一種類型的長尾請求:
SELECT * FROM ontime ORDER BY ArrTime LIMIT 1000;三種執行計劃均為冷啟動查詢,執行時間如下,單位為秒。
行列融合執行 | 純列式執行 | 純行式執行 |
0.33 | 2.56 | 232.48 |
由測試結果可以看出,對于混合型工作負載中的長尾請求,通過“行列融合”執行架構和Hybrid算子兩種方式可以實現最優的性能,相對于純列式執行或純行式執行時間都有數量級的提升。