向量檢索介紹與使用
表格存儲(chǔ)向量檢索(KnnVectorQuery)使用數(shù)值向量進(jìn)行近似最近鄰查詢,可以在大規(guī)模數(shù)據(jù)集中找到最相似的數(shù)據(jù)項(xiàng)。向量檢索功能適用于檢索增強(qiáng)生成(RAG)、推薦系統(tǒng)、相似性檢測、自然語言處理與語義搜索等場景。
應(yīng)用場景
向量檢索適用于推薦系統(tǒng)、圖像與視頻檢索、自然語言處理與語義搜索等場景。
檢索增強(qiáng)生成(RAG)
RAG是一種將檢索能力和大模型能力結(jié)合在一起的AI框架,通過檢索能力增強(qiáng)大模型輸出結(jié)果的準(zhǔn)確性,尤其是在私域數(shù)據(jù)或者專業(yè)數(shù)據(jù)領(lǐng)域可以大幅提升大模型輸出結(jié)果的準(zhǔn)確性。當(dāng)前廣泛應(yīng)用于知識(shí)庫場景。
推薦系統(tǒng)
在電商、社交媒體、視頻流媒體等平臺(tái)中,用戶行為、偏好、內(nèi)容特征等內(nèi)容可以編碼為向量進(jìn)行存儲(chǔ),然后通過向量檢索快速找到與用戶興趣相匹配的產(chǎn)品、文章或視頻,實(shí)現(xiàn)個(gè)性化推薦,提升用戶滿意度和留存率。
相似性檢測(圖像、視頻和語音等)
在圖像,視頻、語音、聲紋和人臉識(shí)別等領(lǐng)域中,可以將這些非結(jié)構(gòu)化的數(shù)據(jù)轉(zhuǎn)換為向量表示,然后通過向量檢索快速找到最相似的目標(biāo)。例如,在電商平臺(tái)中,用戶上傳一張圖片后,系統(tǒng)能迅速找出具有類似樣式、顏色或圖案的商品圖片。
自然語言處理與語義搜索
在NLP領(lǐng)域,將文本轉(zhuǎn)換為向量表示(例如Word2Vec、BERT嵌入等),然后通過向量檢索理解查詢語句的語義,并找出語義上最相關(guān)的文檔、新聞、問答等內(nèi)容,提升搜索結(jié)果的相關(guān)性和用戶體驗(yàn)。
知識(shí)圖譜與智能問答
知識(shí)圖譜節(jié)點(diǎn)和關(guān)系可以表示為向量,通過向量檢索能夠加速實(shí)體鏈接、關(guān)系推理以及智能問答系統(tǒng)的響應(yīng)速度,使系統(tǒng)能夠更準(zhǔn)確地理解和回答復(fù)雜的問題。
功能概述
向量檢索(KnnVectorQuery)使用數(shù)值向量進(jìn)行近似最近鄰查詢,可以在大規(guī)模數(shù)據(jù)集中找到最相似的數(shù)據(jù)項(xiàng)。
向量檢索繼承了多元索引的所有特性,無需部署搭建系統(tǒng),即開即用,按量付費(fèi)。支持多元索引的流式構(gòu)建,數(shù)據(jù)寫入表后近實(shí)時(shí)可查詢;支持高吞吐的新增、更新和刪除;查詢性能和采用HNSW算法的系統(tǒng)相當(dāng)。
使用KnnVectorQuery功能查詢數(shù)據(jù)時(shí),您可以需要指定要查詢相似度的向量、要匹配的向量字段以及要查詢的最鄰近TopK個(gè)值,來獲取向量字段中與要查詢相似度的向量最相似的TopK個(gè)值。您還可以組合使用其他非向量檢索的查詢功能來過濾查詢結(jié)果。
向量字段說明
使用KnnVectorQuery功能前,您需要在創(chuàng)建多元索引時(shí)配置向量字段并指定向量維度、向量數(shù)據(jù)類型和向量之間的距離度量算法。
向量字段在數(shù)據(jù)表中對應(yīng)字段的數(shù)據(jù)類型必須為字符串類型,在多元索引中的數(shù)據(jù)類型必須為Float32數(shù)組字符串。向量字段的具體配置說明請參見下表。
配置項(xiàng) | 說明 |
dimension | 向量維度,當(dāng)前最大支持2048維。維度值必須和上游向量生成(embedded)系統(tǒng)產(chǎn)生的向量維度一致。 向量字段的數(shù)組長度與該字段的dimension參數(shù)配置相等,例如向量字段的值為 說明 當(dāng)前僅支持稠密向量,多元索引中向量字段的數(shù)據(jù)維度必須和創(chuàng)建索引時(shí)Schema中設(shè)置的維度保持一致。如果過多或者過少都會(huì)導(dǎo)致該行數(shù)據(jù)構(gòu)建索引失敗。 |
dataType | 向量的數(shù)據(jù)類型。當(dāng)前僅支持Float32,并且Float32不支持NaN和Infinite等極端值。 數(shù)據(jù)類型必須和上游向量生成(embedded)系統(tǒng)產(chǎn)生的向量數(shù)據(jù)類型保持一致。 說明 如果有其他數(shù)據(jù)類型的向量使用需求,請提交工單聯(lián)系我們。 |
metricType | 向量之間的距離度量算法。取值范圍包括歐氏距離(euclidean)、余弦相似度(cosine)、點(diǎn)積(dot_product)。 距離度量算法必須和上游向量生成(embedded)系統(tǒng)的建議算法保持一致。 更多信息,請參見距離度量算法說明。 |
向量生成(embedded)系統(tǒng)的不同模型或者不同版本生成的向量屬性不同,包括維度、數(shù)據(jù)類型和距離度量算法。向量檢索系統(tǒng)中的向量字段的屬性(維度、數(shù)據(jù)類型和距離度量算法)必須和向量生成(embedded)系統(tǒng)中生成的向量屬性保持一致。關(guān)于向量生成的具體操作,請參見兩種生成向量的方式。
距離度量算法說明
向量檢索支持的距離度量算法包括歐氏距離(euclidean)、余弦相似度(cosine)、點(diǎn)積(dot_product)。具體說明請參見下表。評分公式的值越大表示兩個(gè)向量的相似度越大。
MetricType | 評分公式 | 性能 | 說明 |
歐氏距離 (euclidean) | 較高 | 多維空間中兩個(gè)向量之間的直線距離。出于性能考慮,表格存儲(chǔ)中的歐氏距離算法未進(jìn)行最后的平方根計(jì)算。歐氏距離的評分越大表示兩個(gè)向量的相似度越大。 | |
點(diǎn)積 (dot_product) | 最高 | 維度相同的兩個(gè)向量的對應(yīng)坐標(biāo)相乘,然后將結(jié)果相加。點(diǎn)積的評分越高表示兩個(gè)向量的相似度越大。 Float32向量必須在寫入表前進(jìn)行歸一化(例如使用L2范數(shù)進(jìn)行歸一化),否則會(huì)出現(xiàn)查詢效果差、構(gòu)建向量索引慢、查詢性能差等潛在問題。 | |
余弦相似度 (cosine) | 較低 | 向量空間中兩個(gè)向量間夾角的余弦值。余弦相似度的評分越高表示兩個(gè)向量的相似度越大。常用于文本數(shù)據(jù)的相似度計(jì)算。 由于0無法作為除數(shù),無法完成余弦相似度的計(jì)算,因此Float32向量的平方和不允許為0 余弦相似度計(jì)算復(fù)雜,推薦您在寫入數(shù)據(jù)到表之前進(jìn)行向量的歸一化,然后使用點(diǎn)積(dot_product)作為向量距離的度量算法。 |
產(chǎn)品核心優(yōu)勢
低成本
核心引擎采用優(yōu)化后的DiskAnn技術(shù),相較于HNSW算法,無需加載所有索引數(shù)據(jù)到內(nèi)存,只需不到10%的內(nèi)存即可達(dá)到HNSW圖算法的高召回率和高性能,使整體成本顯著低于同類型系統(tǒng)。
簡單易用
向量檢索作為多元索引的一個(gè)子功能,也具備Serverless特性,用戶無需搭建部署系統(tǒng),只需通過表格存儲(chǔ)控制臺(tái)創(chuàng)建實(shí)例即可開始使用。
使用過程中支持按量付費(fèi),無需關(guān)心水位和擴(kuò)容,系統(tǒng)在存儲(chǔ)和計(jì)算上均支持水平擴(kuò)展。向量檢索最大可以支持千億規(guī)模,非向量檢索最大可以支持十萬億規(guī)模。
向量檢索時(shí)內(nèi)部引擎使用查詢優(yōu)化器自動(dòng)選擇最佳算法和執(zhí)行路徑,無需進(jìn)行眾多參數(shù)的調(diào)優(yōu)即可達(dá)到高召回率和高性能,大幅降低使用門檻,有效縮短業(yè)務(wù)研發(fā)周期。
支持通過SQL、多種SDK(Java、Golang、Python和Node.js等語言)和開源框架(Langchain、LangChain4J和LlamaIndex)等方式使用向量檢索。
計(jì)費(fèi)說明
公測期間,使用向量索引不引入額外的向量索引專用計(jì)費(fèi)項(xiàng),當(dāng)前按照已有模式進(jìn)行計(jì)費(fèi)。
使用VCU模式(原預(yù)留模式)時(shí),使用多元索引查詢數(shù)據(jù)會(huì)消耗VCU的計(jì)算資源。使用CU模式(原按量模式)時(shí),使用多元索引查詢數(shù)據(jù)會(huì)消耗讀吞吐量。更多信息,請參見多元索引計(jì)量計(jì)費(fèi)。
前提條件
創(chuàng)建多元索引時(shí)已配置向量字段。具體操作,請參見創(chuàng)建多元索引。
如果已創(chuàng)建多元索引,您可以通過動(dòng)態(tài)修改Schema修改多元索引的Schema。具體操作,請參見動(dòng)態(tài)修改schema。
注意事項(xiàng)
使用向量檢索時(shí),請注意如下事項(xiàng):
向量字段類型的個(gè)數(shù)、維度等存在限制。更多信息,請參見多元索引限制。
由于多元索引服務(wù)端是多分區(qū)的,多元索引服務(wù)端的每個(gè)分區(qū)均會(huì)返回自身最鄰近的TopK個(gè)值并在協(xié)調(diào)節(jié)點(diǎn)進(jìn)行匯總,因此如果要使用Token翻頁獲取所有數(shù)據(jù),則獲取到的總行數(shù)與多元索引服務(wù)端的分區(qū)數(shù)有關(guān)。
目前支持使用向量檢索功能的地域包括華東1(杭州)、華東1 金融云、華東2(上海)、華北1(青島)、華北2(北京)、華北3(張家口)、華南1(深圳)、華南3(廣州)、西南1(成都)、中國香港、新加坡、馬來西亞(吉隆坡)、印度尼西亞(雅加達(dá))、日本(東京)、德國(法蘭克福)、英國(倫敦)和菲律賓(馬尼拉)。
接口
向量檢索的接口為Search,具體的Query類型為KnnVectorQuery。
參數(shù)
參數(shù) | 是否必選 | 說明 |
fieldName | 是 | 向量字段名稱。 |
topK | 是 | 查詢最鄰近的topK個(gè)值。關(guān)于最大值的說明請參見多元索引限制。 重要
|
float32QueryVector | 是 | 要查詢相似度的向量。 |
filter | 否 | 查詢過濾器,支持組合使用任意的非向量檢索的查詢條件。 |
使用方式
如果使用向量檢索功能時(shí)遇到問題,請提交工單或者加入釘釘群36165029092(表格存儲(chǔ)技術(shù)交流群-3)聯(lián)系我們。
您可以使用控制臺(tái)或者SDK進(jìn)行向量檢索。進(jìn)行向量檢索之前,您需要完成如下準(zhǔn)備工作。
使用阿里云賬號或者使用具有表格存儲(chǔ)操作權(quán)限的RAM用戶進(jìn)行操作。如果需要為RAM用戶授權(quán)表格存儲(chǔ)操作權(quán)限,請參見通過RAM Policy為RAM用戶授權(quán)進(jìn)行配置。
使用SDK方式和命令行工具方式進(jìn)行操作時(shí),如果當(dāng)前無可用AccessKey,則需要為阿里云賬號或者RAM用戶創(chuàng)建AccessKey。具體操作,請參見創(chuàng)建AccessKey。
已創(chuàng)建數(shù)據(jù)表。具體操作,請參見數(shù)據(jù)表操作。
已為數(shù)據(jù)表創(chuàng)建多元索引。具體操作,請參見創(chuàng)建多元索引。
在創(chuàng)建多元索引時(shí)需要配置向量字段。
使用SDK方式進(jìn)行操作時(shí),還需要完成初始化Client。具體操作,請參見初始化OTSClient。
進(jìn)入索引管理頁簽。
在頁面上方,選擇資源組和地域。
在概覽頁面,單擊實(shí)例名稱或在操作列單擊實(shí)例管理。
在實(shí)例詳情頁簽下的數(shù)據(jù)表列表頁簽,單擊數(shù)據(jù)表名稱或在操作列單擊索引管理。
在索引管理頁簽,單擊目標(biāo)多元索引操作列的搜索。
在查詢數(shù)據(jù)對話框,查詢數(shù)據(jù)。
系統(tǒng)默認(rèn)返回所有列,如需顯示指定屬性列,關(guān)閉獲取所有列并輸入需要返回的屬性列,多個(gè)屬性列之間用半角逗號(,)隔開。
說明系統(tǒng)默認(rèn)會(huì)返回?cái)?shù)據(jù)表的主鍵列。
根據(jù)需要選擇邏輯操作符為And、Or或者Not。
當(dāng)選擇邏輯操作符為And時(shí),返回滿足指定條件的數(shù)據(jù)。當(dāng)選擇邏輯操作符為Or時(shí),如果配置了單個(gè)條件,則返回滿足指定條件的數(shù)據(jù);如果配置了多個(gè)條件,則返回滿足任意一個(gè)條件的數(shù)據(jù)。當(dāng)選擇邏輯操作符為Not時(shí),返回不滿足指定條件的數(shù)據(jù)。
選擇向量字段,單擊添加。
設(shè)置向量字段的查詢類型為向量檢索(KnnVectorQuery)以及輸入要查詢的向量和topK值。
請按照界面提示輸入符合格式的向量。
系統(tǒng)默認(rèn)關(guān)閉排序功能,如需根據(jù)指定字段對返回結(jié)果進(jìn)行排序,打開是否排序開關(guān)后,根據(jù)需要添加要進(jìn)行排序的字段并配置排序方式。
系統(tǒng)默認(rèn)關(guān)閉統(tǒng)計(jì)功能,如需對指定字段進(jìn)行數(shù)據(jù)統(tǒng)計(jì),打開是否統(tǒng)計(jì)開關(guān)后,根據(jù)需要添加要進(jìn)行統(tǒng)計(jì)的字段和配置統(tǒng)計(jì)信息。
單擊確定。
符合查詢條件的數(shù)據(jù)會(huì)顯示在索引管理頁簽中。
表格存儲(chǔ)Java SDK從5.17.0版本開始支持向量檢索,Go SDK請使用最新SDK版本,Python SDK從5.4.4版本開始支持向量檢索,Node.js SDK從5.5.0版本開始支持向量檢索。
您可以通過Java SDK、Go SDK、Python SDK或Node.js SDK使用向量檢索功能。此處以Java SDK為例介紹使用向量檢索的操作。
以下示例用于查詢表中與指定向量最鄰近的10個(gè)向量數(shù)據(jù),并且最鄰近的向量需要滿足Col_Keyword列值等于"hangzhou"且Col_Long列值小于4的條件。
private static void knnVectorQuery(SyncClient client) {
SearchQuery searchQuery = new SearchQuery();
KnnVectorQuery query = new KnnVectorQuery();
query.setFieldName("Col_Vector");
query.setTopK(10); // 返回最鄰近的topK。
query.setFloat32QueryVector(new float[]{0.1f, 0.2f, 0.3f, 0.4f});
// 最鄰近的向量需要滿足Col_Keyword=hangzhou && Col_Long<4條件。
query.setFilter(QueryBuilders.bool()
.must(QueryBuilders.term("Col_Keyword", "hangzhou"))
.must(QueryBuilders.range("Col_Long").lessThan(4))
);
searchQuery.setQuery(query);
searchQuery.setLimit(10);
// 按照分?jǐn)?shù)排序。
searchQuery.setSort(new Sort(Collections.singletonList(new ScoreSort())));
SearchRequest searchRequest = new SearchRequest("<TABLE_NAME>", "<SEARCH_INDEX_NAME>", searchQuery);
SearchRequest.ColumnsToGet columnsToGet = new SearchRequest.ColumnsToGet();
columnsToGet.setColumns(Arrays.asList("Col_Keyword", "Col_Long"));
searchRequest.setColumnsToGet(columnsToGet);
// 訪問Search接口。
SearchResponse resp = client.search(searchRequest);
for (SearchHit hit : resp.getSearchHits()) {
// 打印分?jǐn)?shù)。
System.out.println(hit.getScore());
// 打印數(shù)據(jù)。
System.out.println(hit.getRow());
}
}相關(guān)文檔
多元索引查詢類型包括精確查詢、多詞精確查詢、全匹配查詢、匹配查詢、短語匹配查詢、前綴查詢、范圍查詢、通配符查詢、基于分詞的通配符查詢、多條件組合查詢、地理位置查詢、嵌套類型查詢、向量檢索介紹與使用和列存在性查詢,您可以選擇合適的查詢類型進(jìn)行多維度數(shù)據(jù)查詢。
如果要對結(jié)果集進(jìn)行排序或者翻頁,您可以使用排序和翻頁功能來實(shí)現(xiàn)。具體操作,請參見排序和翻頁。
如果要按照某一列對結(jié)果集做折疊,使對應(yīng)類型的數(shù)據(jù)在結(jié)果展示中只出現(xiàn)一次,您可以使用折疊(去重)功能來實(shí)現(xiàn)。具體操作,請參見折疊(去重)。
如果要進(jìn)行數(shù)據(jù)分析,例如求最值、求和、統(tǒng)計(jì)行數(shù)等,您可以使用Search接口的統(tǒng)計(jì)聚合功能或者SQL查詢來實(shí)現(xiàn)。具體操作,請參見統(tǒng)計(jì)聚合和SQL查詢。
如果要快速導(dǎo)出數(shù)據(jù),而不關(guān)心整個(gè)結(jié)果集的順序時(shí),您可以使用ParallelScan接口和ComputeSplits接口實(shí)現(xiàn)多并發(fā)導(dǎo)出數(shù)據(jù)。具體操作,請參見并發(fā)導(dǎo)出數(shù)據(jù)。
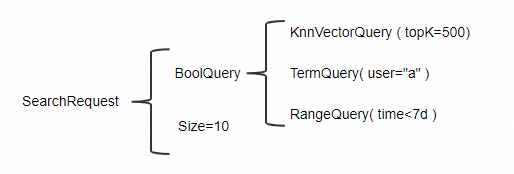
附錄1:與BoolQuery組合使用說明
KnnVectorQuery可以和BoolQuery自由組合使用,不同的組合使用方式會(huì)有不同的效果,以下對兩種常見的使用方式進(jìn)行說明。此處以一個(gè)Filter命中數(shù)據(jù)量較少的場景為例進(jìn)行介紹。
假設(shè)表中有1億張圖片,其中用戶“a”總計(jì)有5萬張圖片,但是近7天內(nèi)僅有50張圖片,用戶“a”希望以圖搜圖的方式找到7天內(nèi)最相似的10張圖片。由下表說明可知KnnVectorQuery的Filter內(nèi)部使用BoolQuery的組合使用方式能滿足用戶“a”的查詢需求。
組合使用方式 | 查詢條件圖示 | 說明 |
KnnVectorQuery的Filter內(nèi)部使用BoolQuery |
| KnnVectorQuery命中的行數(shù)據(jù)為在滿足BoolQuery條件下返回最相似的TopK個(gè)行數(shù)據(jù),SearchRequest返回的結(jié)果為TopK行數(shù)中的前Size個(gè)。 在此示例中,KnnVectorQuery首先通過Filter篩選出該用戶“a”在7天內(nèi)的所有50張圖片,然后再從50張圖片中找到最相似的10張圖片返回給用戶。 |
BoolQuery中使用KnnVectorQuery |
| BoolQuery的每一個(gè)子查詢條件會(huì)首先進(jìn)行查詢,然后對所有子查詢求交集。 在此示例中,KnnVectorQuery會(huì)返回表中1億張圖片中最相似的前TopK=500張圖片,然后再按照順序找出用戶“a”在7天內(nèi)的10張圖片。但是由于所有圖片的TopK=500張圖片中不一定包含用戶“a”近7天內(nèi)所有的50張圖片,因此該查詢方式不一定能找到近7天內(nèi)的10張圖片,甚至找不到任何數(shù)據(jù)。 |

附錄2:向量歸一化示例
向量歸一化的示例代碼如下:
public static float[] l2normalize(float[] v, boolean throwOnZero) {
double squareSum = 0.0f;
int dim = v.length;
for (float x : v) {
squareSum += x * x;
}
if (squareSum == 0) {
if (throwOnZero) {
throw new IllegalArgumentException("can't normalize a zero-length vector");
} else {
return v;
}
}
double length = Math.sqrt(squareSum);
for (int i = 0; i < dim; i++) {
v[i] /= length;
}
return v;
}