如果要以更低成本備份表格存儲中的全量數據或者以文件形式導出表格存儲數據到本地,您可以通過DataWorks數據集成服務將表格存儲中的全量數據導出到OSS。全量數據導出到OSS后,您可以自由下載文件到本地。
注意事項
此功能適用于表格存儲寬表模型和時序模型。
準備工作
已開通OSS服務并創建存儲空間Bucket。具體操作,請參見開通OSS服務和通過控制臺創建存儲空間。
已確認和記錄表格存儲中要同步到OSS的實例、數據表或者時序表信息。
已開通DataWorks服務并創建工作空間。具體操作,請參見開通DataWorks服務和創建工作空間。
已創建RAM用戶并為RAM用戶授予OSS完全管理權限(AliyunOSSFullAccess)和管理表格存儲權限(AliyunOTSFullAccess)。具體操作,請參見創建RAM用戶和為RAM用戶授權。
重要由于配置時需要填寫訪問密鑰AccessKey(AK)信息來執行授權,為避免阿里云賬號泄露AccessKey帶來的安全風險,建議您通過RAM用戶來完成授權和AccessKey的創建。
已為RAM用戶創建AccessKey。具體操作,請參見創建AccessKey。
步驟一:新增表格存儲數據源
將表格存儲數據庫添加為數據源,具體步驟如下:
進入數據集成頁面。
以項目管理員身份登錄DataWorks控制臺。
在左側導航欄,單擊工作空間列表后,選擇地域。
在工作空間列表頁面,在目標工作空間操作列選擇快速進入>數據集成。
在左側導航欄,單擊數據源。
在數據源頁面,單擊新增數據源。
在新增數據源對話框,找到Tablestore區塊,單擊Tablestore。
在新增OTS數據源對話框,根據下表配置數據源參數。
參數
說明
數據源名稱
數據源名稱必須以字母、數字、下劃線(_)組合,且不能以數字和下劃線(_)開頭。
數據源描述
對數據源進行簡單描述,不得超過80個字符。
Endpoint
Tablestore實例的服務地址。更多信息,請參見服務地址。
如果Tablestore實例和目標數據源的資源在同一個地域,填寫VPC地址;如果Tablestore實例和目標數據源的資源不在同一個地域,填寫公網地址。
Table Store實例名稱
Tablestore實例的名稱。更多信息,請參見實例。
AccessKey ID
阿里云賬號或者RAM用戶的AccessKey ID和AccessKey Secret。獲取方式請參見創建AccessKey。
AccessKey Secret
測試資源組連通性。
創建數據源時,您需要測試資源組的連通性,以保證同步任務使用的資源組能夠與數據源連通,否則將無法正常執行數據同步任務。
重要數據同步時,一個任務只能使用一種資源組。資源組列表默認僅顯示獨享數據集成資源組,為確保數據同步的穩定性和性能要求,推薦使用獨享數據集成資源組。
如果未創建資源組,請單擊新建獨享數據集成資源組進行創建。具體操作,請參見新增和使用獨享數據集成資源組。
單擊相應資源組操作列的測試連通性,當連通狀態為可連通時,表示連通成功。
測試連通性通過后,單擊完成。
在數據源列表中,可以查看新建的數據源。
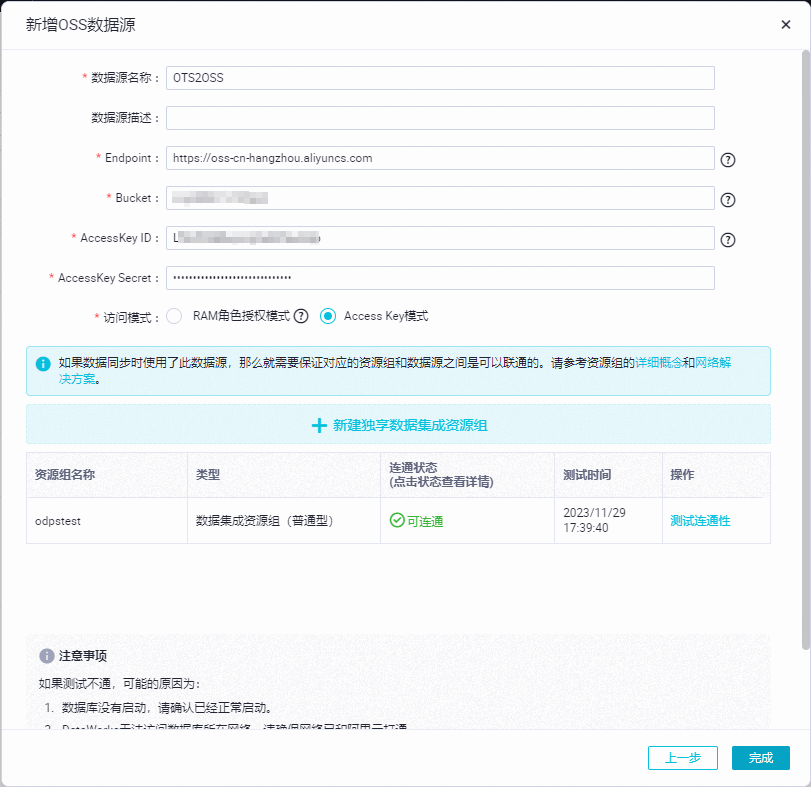
步驟二:新增OSS數據源
具體操作與步驟一類似,只需在新增數據源對話框,找到OSS區塊,單擊OSS。
本示例中,該數據源名稱使用OTS2OSS,如下圖所示。
配置OSS數據源的參數時,請注意Endpoint中不能包括Bucket的名稱,且必須以
http://或者https://開頭。對OSS的訪問支持Access Key模式和RAM角色授權模式,請根據實際選擇。
Access Key模式:通過阿里云賬號或者RAM用戶的AccessKey ID和AccessKey Secret訪問數據源。
RAM角色授權模式:通過STS授權的方式允許云產品服務賬號扮演相關角色來訪問數據源,具備更高安全性。更多信息,請參見通過RAM角色授權模式配置數據源。
首次選擇訪問模式為RAM角色授權模式時,系統會顯示警告對話框,提示創建相關服務關聯角色的信息,單擊開啟授權進行授權。開啟授權后,選擇角色為新建的服務關聯角色。
步驟三:新建同步任務節點
進入數據開發頁面。
以項目管理員身份登錄DataWorks控制臺。
選擇地域,在左側導航欄,單擊工作空間列表。
在工作空間列表頁面,在目標工作空間操作列選擇快速進入>數據開發。
在DataStudio控制臺的數據開發頁面,單擊業務流程節點下的目標業務流程。
如果需要新建業務流程,請參見創建業務流程。
在數據集成節點上右鍵選擇新建節點 > 離線同步。
在新建節點對話框,選擇路徑并填寫節點名稱。
單擊確認。
在數據集成節點下會顯示新建的離線同步節點。
步驟四:配置離線同步任務并啟動
配置表格存儲到OSS的全量數據同步任務,請根據所用數據存儲模型選擇相應任務配置方式。
如果所用的數據存儲模型是寬表模型(即使用數據表存儲數據),則需要同步數據表中的數據,請按照同步數據表數據的任務配置進行配置。
如果所用的數據存儲模型是時序模型(即使用時序表存儲數據),則需要同步時序表中的數據,請按照同步時序表數據的任務配置進行配置。
同步數據表數據的任務配置
在數據集成節點下,雙擊打開新建的離線同步任務節點。
配置同步網絡鏈接。
選擇離線同步任務的數據來源、數據去向以及用于執行同步任務的資源組,并測試連通性。
重要數據同步任務的執行必須經過資源組來實現,請選擇資源組并保證資源組與讀寫兩端的數據源能聯通訪問。
在網絡與資源配置步驟,選擇數據來源為Tablestore,并選擇數據源名稱為步驟一:新增表格存儲數據源中新增的源數據源。
選擇資源組。
選擇資源組后,系統會顯示資源組的地域、規格等信息以及自動測試資源組與所選數據源之間連通性。
重要請與新增數據源時選擇的資源組保持一致。
選擇數據去向為OSS,并選擇數據源名稱為步驟二:新增OSS數據源中新增的目的數據源。
系統會自動測試資源組與所選數據源之間連通性。
測試可連通后,單擊下一步。
配置任務。
您可以通過向導模式或者腳本模式配置同步任務,請根據實際需要選擇。
(推薦)向導模式
在配置任務步驟的配置數據來源與去向區域,根據實際配置數據來源和數據去向。
數據來源配置
參數
說明
表
表格存儲中的數據表名稱。
主鍵區間分布(起始)
數據讀取的起始主鍵和結束主鍵,格式為JSON數組。
起始主鍵和結束主鍵需要是有效的主鍵或者是由INF_MIN和INF_MAX類型組成的虛擬點,虛擬點的列數必須與主鍵相同。
其中INF_MIN表示無限小,任何類型的值都比它大;INF_MAX表示無限大,任何類型的值都比它小。
數據表中的行按主鍵從小到大排序,讀取范圍是一個左閉右開的區間,返回的是大于等于起始主鍵且小于結束主鍵的所有的行。
假設表包含pk1(String類型)和pk2(Integer類型)兩個主鍵列。
如果需要導出全表數據,則配置示例如下:
主鍵區間分布(起始)的配置示例
[ { "type": "INF_MIN" }, { "type": "INF_MIN" } ]主鍵區間分布(結束)的配置示例
[ { "type": "INF_MAX" }, { "type": "INF_MAX" } ]
如果需要導出
pk1="tablestore"的行,則配置示例如下:主鍵區間分布(起始)的配置示例
[ 。 { "type": "STRING", "value": "tablestore" }, { "type": "INF_MIN" } ]主鍵區間分布(結束)的配置示例
[ { "type": "STRING", "value": "tablestore" }, { "type": "INF_MAX" } ]
主鍵區間分布(結束)
切分配置信息
自定義切分配置信息,普通情況下不建議配置。當Tablestore數據存儲發生熱點,且使用Tablestore Reader自動切分的策略不能生效時,建議使用自定義的切分規則。切分指定的是在主鍵起始和結束區間內的切分點,僅配置切分鍵,無需指定全部的主鍵。格式為JSON數組。
數據去向配置
參數
說明
文本類型
寫入OSS的文件類型,例如csv、txt。
說明不同文件類型支持的配置有差異,請以實際界面為準。
文件名(含路徑)
當設置文本類型為text、csv或orc時才能配置該參數。
OSS中的文件名稱,支持帶有路徑,例如
tablestore/20231130/myotsdata.csv。文件路徑
當設置文本類型為parquet時才能配置該參數。
文件在OSS上的路徑,例如
tablestore/20231130/。文件名
當設置文本類型為parquet時才能配置該參數。
OSS中的文件名稱。
列分隔符
當設置文本類型為text或csv時才能配置該參數。
寫入OSS文件時,列之間使用的分隔符。
行分隔符
當設置文本類型為text時才能配置才參數。
自定義的行分隔符,用來分隔不同數據行。例如配置為
\u0001。您需要使用數據中不存在的分隔符作為行分隔符。如果要使用Linux或Windows平臺的默認行分隔符(
\n、\r\n)建議置空此配置,平臺能自適應讀取。編碼
當設置文本類型為text或csv時才能配置該參數。
寫入文件的編碼配置。
null值
當設置文本類型為text、csv或orc時才能配置該參數。
源數據源中可以表示為null的字符串,例如配置為null,如果源數據是null,則系統會視作null字段。
時間格式
當設置文本類型為text或csv時才能配置該參數。
日期類型的數據寫入到OSS文件時的時間格式,例如
yyyy-MM-dd。前綴沖突
當設置的文件名與OSS中已有文件名沖突時的處理方法。取值范圍如下:
替換:刪除原始文件,重建一個同名文件。
保留:保留原始文件,重建一個新文件,名稱為原文件名加隨機后綴。
報錯:同步任務停止執行。
切分文件
當設置文本類型為text或csv時才能配置該參數。
寫入OSS文件時,單個Object文件的最大大小。單位為MB。最大值為100 GB。當文件大小超過指定的切分文件大小時,系統會生成新文件繼續寫入數據,直到完成所有數據寫入。
寫為一個文件
當設置文本類型為text或csv時才能配置該參數。
寫入數據到OSS時,是否寫單個文件。默認寫多個文件,當讀不到任何數據時,如果配置了文件頭,則會輸出只包含文件頭的空文件,否則只輸出空文件。
如果需要寫入到單個文件,請選中寫為一個文件復選框。此時當讀不到任何數據時, 不會產生空文件。
首行輸出表頭
當設置文本類型為text或csv時才能配置該參數。
寫入文件時第一行是否輸出表頭。默認不輸出表頭。如果需要在第一行輸出表頭,請選中首行輸出表頭復選框。
在字段映射區域,單擊來源字段后的
 圖標,手動編輯要同步到OSS的來源字段,目標字段無需配置。
圖標,手動編輯要同步到OSS的來源字段,目標字段無需配置。在通道控制區域,配置任務運行參數,例如同步速率、臟數據同步策略等。關于參數配置的更多信息,請參見配置通道。
單擊
 圖標,保存配置。說明
圖標,保存配置。說明執行后續操作時,如果未保存配置,則系統會出現保存確認的提示,單擊確認即可。
腳本模式
全量數據的同步需要使用到Tablestore(OTS) Reader和OSS Writer插件。腳本配置規則請參見Tablestore數據源和OSS數據源。
重要任務轉為腳本模式后,將無法轉為向導模式,請謹慎操作。
在配置任務步驟,單擊
 圖標,然后在彈出的對話框中單擊確認。
圖標,然后在彈出的對話框中單擊確認。在腳本配置頁面,請根據如下示例完成配置。
重要由于全量導出一般是一次性的,所以無需配置自動調度參數。如果需要配置調度參數,請參見增量同步中的調度參數配置。
如果在腳本配置中存在變量,例如存在
${date},則需要在運行同步任務時設置變量的具體值。為了便于理解,在配置示例中增加了注釋內容,實際使用腳本時請刪除所有注釋內容。
{ "type": "job", //不能修改。 "version": "2.0", //版本號,不能修改。 "steps": [ { "stepType":"ots",//插件名,不能修改。 "parameter":{ "datasource":"otssource",//表格存儲數據源名稱,請根據實際填寫。 "newVersion":"true",//使用新版otsreader。 "mode": "normal",// 行模式讀取數據。 "isTimeseriesTable":"false",// 配置該表為寬表(非時序表)。 "column":[//需要導出到OSS的列名,不能設置為空。 { "name":"column1"http://Tablestore中列名,此列需要導入到OSS。 }, { "name":"column2" }, { "name":"column3" }, { "name":"column4" }, { "name":"column5" } ], "range":{ "split":[ //用于配置Tablestore的數據表的分區信息,可以加速導出。一般情況下無需配置。 ], "end":[//Tablestore中結束主鍵信息。如果需要導出全量數據,此處請配置為INF_MAX;如果只需導出部分數據,則按需配置。當數據表存在多個主鍵列時,此處end中需要配置對應主鍵列信息。 { "type":"STRING", "value":"endValue" }, { "type":"INT", "value":"100" }, { "type":"INF_MAX" }, { "type":"INF_MAX" } ], "begin":[//Tablestore中起始主鍵信息。如果需要導出全量數據,此處請配置為INF_MIN;如果只需導出部分數據,則按需配置。當數據表存在多個主鍵列時,此處begin中需要配置對應主鍵列信息。 { "type":"STRING", "value":"beginValue" }, { "type":"INT", "value":"0" }, { "type":"INF_MIN" }, { "type":"INF_MIN" } ] }, "table":"datatable"http://Tablestore中的數據表名稱。 }, "name":"Reader", "category":"reader" }, { "stepType": "oss",//插件名,不能修改。 "parameter": { "nullFormat": "null", //定義null值的字符串標識符方式,可以是空字符串。 "dateFormat": "yyyy-MM-dd HH:mm:ss",//日期格式。 "datasource": "osssource", //OSS數據源名稱,請根據實際填寫。 "envType": 1, "writeSingleObject": true, //將同步數據寫入單個oss文件。 "writeMode": "truncate", //當同名文件存在時系統進行的操作,全量導出時請使用truncate,可選值包括truncate、append和nonConflict。truncate表示會清理已存在的同名文件,append表示會增加到已存在的同名文件內容后面,nonConflict表示當同名文件存在時會報錯。 "encoding": "UTF-8", //編碼類型。 "fieldDelimiter": ",", //每一列的分隔符。 "fileFormat": "csv", //導出的文本類型,取值范圍包括csv、text、parquet和orc。 "object": "tablestore/20231130/myotsdata.csv" //Object的前綴,無需包括Bucket名稱,例如tablestore/20231130/。如果是定時導出,則此處需要使用變量,例如tablestore/${date},然后在配置調度參數時配置${date}的值。 }, "name": "Writer", "category": "writer" }, { "name": "Processor", "stepType": null, "category": "processor", "copies": 1, "parameter": { "nodes": [], "edges": [], "groups": [], "version": "2.0" } } ], "setting": { "executeMode": null, "errorLimit": { "record": "0" //當錯誤個數超過record個數時,導入任務會失敗。 }, "speed": { "concurrent": 2, //并發度。 "throttle": false } }, "order": { "hops": [ { "from": "Reader", "to": "Writer" } ] } }單擊
圖標,保存配置。說明執行后續操作時,如果未保存腳本,則系統會出現保存確認的提示,單擊確認即可。
執行同步任務。
重要全量數據一般只需要同步一次,無需配置調度屬性。
單擊
 圖標。
圖標。在參數對話框,選擇運行資源組的名稱。
單擊運行。
運行結束后,在同步任務的運行日志頁簽,單擊Detail log url對應的鏈接后。在任務的詳細運行日志頁面,查看
Current task status對應的狀態。當
Current task status的值為FINISH時,表示任務運行完成。
同步時序表數據的任務配置
在數據集成節點下,雙擊打開新建的離線同步任務節點。
配置同步網絡鏈接。
選擇離線同步任務的數據來源、數據去向以及用于執行同步任務的資源組,并測試連通性。
重要數據同步任務的執行必須經過資源組來實現,請選擇資源組并保證資源組與讀寫兩端的數據源能聯通訪問。
在網絡與資源配置步驟,選擇數據來源為Tablestore,并選擇數據源名稱為步驟一:新增表格存儲數據源中新增的源數據源。
選擇資源組。
選擇資源組后,系統會顯示資源組的地域、規格等信息以及自動測試資源組與所選數據源之間連通性。
重要請與新增數據源時選擇的資源組保持一致。
選擇數據去向為OSS,并選擇數據源名稱為步驟二:新增OSS數據源中新增的目的數據源
系統會自動測試資源組與所選數據源之間連通性。
測試可連通后,單擊下一步。
配置任務。
同步時序表數據時只支持使用腳本模式進行任務配置。全量數據的同步需要使用到Tablestore(OTS) Reader和OSS Writer插件。腳本配置規則請參見Tablestore數據源和OSS數據源。
重要任務轉為腳本模式后,將無法轉為向導模式,請謹慎操作。
在配置任務步驟,單擊
圖標,然后在彈出的對話框中單擊確認。在腳本配置頁面,請根據如下示例完成配置。
重要由于全量導出一般是一次性的,所以無需配置自動調度參數。如果需要配置調度參數,請參見增量同步中的調度參數配置。
如果在腳本配置中存在變量,例如存在
${date},則需要在運行同步任務時設置變量的具體值。為了便于理解,在配置示例中增加了注釋內容,實際使用腳本時請刪除所有注釋內容。
{ "type": "job", "version": "2.0", //版本號,不能修改。 "steps": [ { "stepType":"ots",//插件名,不能修改。 "parameter":{ "datasource":"otssource",//表格存儲數據源名稱,請根據實際填寫。 "table": "timeseriestable",//時序表名稱。 // 讀時序數據mode必須為normal。 "mode": "normal", // 讀時序數據newVersion必須為true。 "newVersion": "true", // 配置該表為時序表。 "isTimeseriesTable":"true", // 配置需要讀取時序數據的度量名稱,非必需。如果置空則表示讀取全表數據。 "measurementName":"measurement_1", "column": [ // 度量名稱,name固定取值為_m_name。如果不需要導出該列數據,則無需配置。 { "name": "_m_name" }, //數據源名稱,name固定取值為_data_source。如果不需要導出該列數據,則無需配置。 { "name": "_data_source" }, //數據點的時間戳,單位為微秒。name固定取值為_time,type固定取值為INT。如果不需要導出該列數據,則無需配置。 { //列名。 "name": "_time" //列類型。 "type":"INT" }, //時間線標簽。如果時間線存在多個標簽,您可以配置多個標簽列信息。 { //時間線標簽名稱,請根據實際填寫。 "name": "tagA", //是否為時間線標簽。默認值為false,如果要指定列為標簽,則需要設置此參數為true。 "is_timeseries_tag":"true" }, { "name": "double_0", "type":"DOUBLE" }, { "name": "string_0", "type":"STRING" }, { "name": "long_0", "type":"INT" }, { "name": "binary_0", "type":"BINARY" }, { "name": "bool_0", "type":"BOOL" } ] }, "name":"Reader", "category":"reader" }, { "stepType": "oss",//插件名,不能修改。 "parameter": { "nullFormat": "null", //定義null值的字符串標識符方式,可以是空字符串。 "dateFormat": "yyyy-MM-dd HH:mm:ss",//日期格式。 "datasource": "osssource", //OSS數據源名稱,請根據實際填寫。 "envType": 1, "writeSingleObject": true, //將同步數據寫入單個oss文件。 "writeMode": "truncate", //當同名文件存在時系統進行的操作,全量導出時請使用truncate,可選值包括truncate、append和nonConflict。truncate表示會清理已存在的同名文件,append表示會增加到已存在的同名文件內容后面,nonConflict表示當同名文件存在時會報錯。 "encoding": "UTF-8", //編碼類型。 "fieldDelimiter": ",", //每一列的分隔符。 "fileFormat": "csv", //導出的文本類型,取值范圍包括csv、text、parquet和orc。 "object": "tablestore/20231130/myotsdata.csv" //Object的前綴,無需包括Bucket名稱,例如tablestore/20231130/。如果是定時導出,則此處需要使用變量,例如tablestore/${date},然后在配置調度參數時配置${date}的值。 }, "name": "Writer", "category": "writer" }, { "name": "Processor", "stepType": null, "category": "processor", "copies": 1, "parameter": { "nodes": [], "edges": [], "groups": [], "version": "2.0" } } ], "setting": { "executeMode": null, "errorLimit": { "record": "0" //當錯誤個數超過record個數時,導入任務會失敗。 }, "speed": { "concurrent": 2, //并發度。 "throttle": false } }, "order": { "hops": [ { "from": "Reader", "to": "Writer" } ] } }單擊
圖標,保存配置。說明執行后續操作時,如果未保存腳本,則系統會出現保存確認的提示,單擊確認即可。
執行同步任務。
重要全量數據一般只需要同步一次,無需配置調度屬性。
單擊
圖標。在參數對話框,選擇運行資源組的名稱。
單擊運行。
運行結束后,在同步任務的運行日志頁簽,單擊Detail log url對應的鏈接后。在任務的詳細運行日志頁面,查看
Current task status對應的狀態。當
Current task status的值為FINISH時,表示任務運行完成。
步驟五:查看導出到OSS中的數據
登錄OSS管理控制臺。
在Bucket列表頁面,找到目標Bucket后,單擊Bucket名稱。
在文件列表頁簽,選擇相應文件,下載后可查看內容是否符合預期。
常見問題
相關文檔
將表格存儲的全量數據導出到OSS后,您還可以將表格存儲的增量數據同步到OSS存儲。具體操作,請參見增量同步。
將表格存儲的全量數據導出到OSS后,如果需要快速清理表格存儲表中不再使用的歷史數據,您可以通過數據生命周期功能實現。更多信息,請參見數據生命周期(數據表)或者更新時序表數據生命周期(時序表)。
如果要下載導出的OSS文件到本地,您可以使用OSS控制臺、命令行工具ossutil等工具直接進行下載。更多信息,請參見簡單下載。
為了防止由于誤刪、惡意篡改等導致重要數據不可用,您可以使用表格存儲數據備份功能備份實例中寬表數據,并在數據丟失或受損時及時恢復。更多信息,請參見數據備份概述。
如果要實現表格存儲數據表的冷熱數據分層存儲、全量數據備份表格存儲數據以及大規模實時數據分析,您可以使用表格存儲的數據湖投遞功能實現。更多信息,請參見數據湖投遞。