本文介紹Feed流系統的兩種擴展模型:推拉結合方案和加入排序后的Rank流方案。
推拉結合方案
雖然使用推模式可以滿足Feed流系統需求,但隨著用戶數量增長,數據量也急劇增長。在推模式的工作下,數據量會膨脹得更多。針對這個缺點,可以考慮采用推拉結合的推動方案。
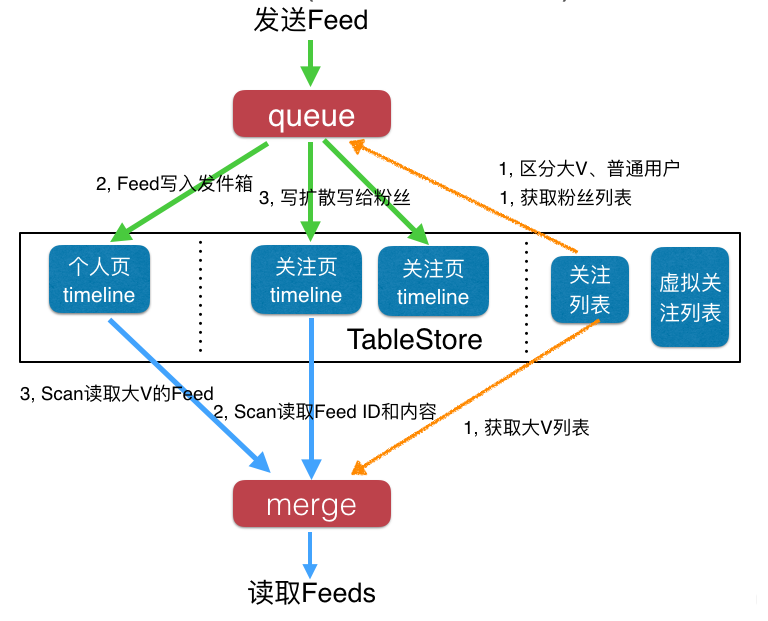
推拉結合是指對大V采用拉模式,而普通用戶使用推模式。此時發布Feed和獲取Feed流的過程如下:
發布Feed
Feed消息先進入一個隊列服務。
先從關注列表中讀取到自己的粉絲列表,以及判斷自己是否是大V。
將自己的Feed消息寫入個人頁Timeline(發件箱)。如果是大V,寫入流程到此結束。
如果是普通用戶,還需要將自己的Feed消息寫給自己的粉絲,如果有100個粉絲,那么就要寫給100個用戶,包括Feed內容和Feed ID。
第三步和第四步可以合并在一起,使用BatchWriteRow接口一次性將多行數據寫入表格存儲。
發布Feed的流程結束。
讀取Feed流
先讀取自己關注的大V列表。
通過GetRange讀取自己的收件箱。范圍起始位置是上次讀取到的最新Feed的ID;結束位置可以是當前時間,也可以是MAX,建議是MAX值。
如果有關注的大V,則再次并發讀取每一個大V的發件箱。如果關注了10個大V,那么則需要10次訪問。
合并2和3步的結果,然后按時間排序,返回給用戶。
如果使用大V/普通用戶的切分,架構存在一定風險。例如某個大V突然發了一個很有話題性的Feed,那么就有可能導致整個Feed產品中的所有用戶都沒法讀取新內容。以粉絲讀取流程為例:
大V發送Feed消息。
大V使用拉模式。
大V的活躍粉絲(用戶群A)開始通過拉模式讀取大V的新Feed。
Feed內容太有話題性,快速傳播。
未登錄的大V粉絲(用戶群B)開始登錄產品,登錄進去后自動刷新,再次通過讀3步驟讀取大V的Feed內容。
非粉絲(用戶群C)去大V的個人頁Timeline里面去圍觀,再次需要讀取大V個人的Timeline,同讀3。
結果就是,平時正常流量只有用戶群A,結果現在卻是用戶群A + 用戶群B + 用戶群C,流量增加了好幾倍,甚至幾十倍,導致讀3路徑的服務模塊被打到server busy或者機器資源被打滿,導致讀取大V的讀3路徑無法返回請求。如果Feed產品中的用戶都有關注大V,那么基本上所有用戶都會卡死在讀取大V的讀3路徑上,然后就沒法刷新了。
所以設計時需重點關心下面兩點:
單個模塊的不可用,不應該阻止整個關鍵的讀Feed流路徑。如果大V的無法讀取,但是普通用戶的要能返回,等服務恢復后,再補齊大V的內容即可。
當模塊無法承受這么大流量的時候,模塊不應該完全不可服務,而應該能繼續提供最大的服務能力,超過的拒絕掉。
優化方法
方法一:不使用大V/普通用戶的優化方式,而使用活躍用戶/非活躍用戶的優化方式,這種優化方式能把用戶群A和部分用戶群B分流到其他更分散的多個路徑上去。而且即使讀3路徑不可用,仍然對活躍用戶無任何影響。
方法二:完全使用推模式可以徹底解決這個問題,但會增大存儲量,并增長大V微博發送總時間,從發給第一個粉絲到發給最后一個粉絲可能要幾分鐘時間(一億粉絲,100萬行每秒,需要100秒),還需要為最大并發預留好資源(如果使用阿里云表格存儲,則不需要考慮預留最大額度資源的問題)。
個性化和定向廣告
個性化和定向廣告是需求度很高的兩個功能。個性化可以服務好用戶,增大產品競爭力和用戶粘性。定向廣告可以為產品增加盈利渠道,而且不引起用戶反感。在Feed流里這兩種功能的實現方式類似,我們以實現定向廣告的流程為例來說明。
通過用戶特征分析對用戶分類,例如今年剛上大學的新生(新生類)。具體的用戶特征分析可以依靠表格存儲 + MaxCompute。
創建一個廣告賬號:新生廣告。
讓這些具有新生特征的用戶虛擬關注新生廣告賬號。用戶側看不到這一層關注關系。
從七月份開始就通過新生廣告賬號發送廣告。
每個用戶可能會有多個特征,那么就可能虛擬關注多個廣告賬號。
基于推薦的Rank流
除了Timeline類型的Feed流類型,Rank類型的Feed流也比較常見。Rank類型的潛在Feed內容非常多,用戶無法全部看完,也不需要全部看完,則需要為用戶選出最想看的內容。Rank類型典型的應用包括圖片分享網站、新聞推薦網站等。
方式一(輕量級)
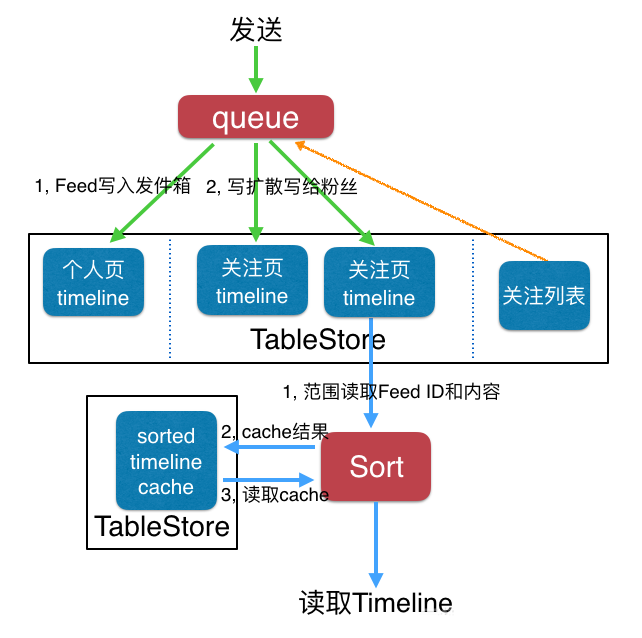
上面架構圖展示的Rank方式比較輕量級,適用于推拉結合的場景。
寫流程和Timeline基本一樣。
讀流程里面會先讀取所有的Feed內容,這個和Timeline一樣。Timeline中這部分會直接返回給用戶,但是Rank類型需要在一個排序模塊里面,按照某個屬性值排序,然后將所有結果存入一個timeline cache中,并返回分數最高的N個結果,下次讀取的時候再返回[N+1, 2N]的結果。
方式二(重量級)

上面架構圖展示的Rank方式比較重量級,適用于純推模式。
寫流程和Timeline一樣。
每個用戶有兩個收件箱。
一個是關注頁Timeline,保存原始的Feed內容,用戶無法直接查看這個收件箱。
一個是rank timeline,保存為用戶精選的Feed內容,用戶直接查看這個收件箱。
寫流程結束后還有一個數據處理的流程。個性化排序系統從原始Feed收件箱中獲取到新的Feed內容,按照用戶的特征、Feed的特征計算出一個分數。每個Feed在不同用戶的Timeline中可能分數不一樣的,計算完成后再排序然后寫入最終的rank timeline。