多元索引(Search Index)基于倒排索引和列式存儲,可以解決大數據的多維查詢和統計分析難題。當日常業務中有非主鍵列查詢、多列組合查詢、模糊查詢、全文檢索和向量檢索等復雜查詢需求以及求最值、統計行數、數據分組等數據分析需求時,您可以將這些屬性作為多元索引中的字段并使用多元索引查詢與分析數據。
背景信息
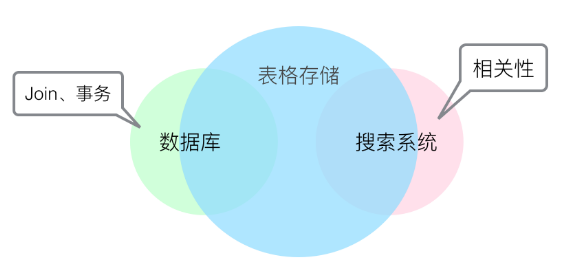
多元索引可以解決大數據中復雜的查詢問題,同時數據庫、搜索引擎等其他系統也可以解決數據的查詢問題。
表格存儲與數據庫及搜索引擎等系統的主要區別如下:
除了Join、事務和相關性外,表格存儲能覆蓋數據庫和搜索系統中的其他功能,同時具備數據庫的數據高可靠性和搜索系統的高級查詢能力,可以替換常見的數據庫 + 搜索系統組合架構方式。如果您的使用場景中不需要Join、事務和復雜相關性時,您可以選擇使用表格存儲多元索引。
索引介紹
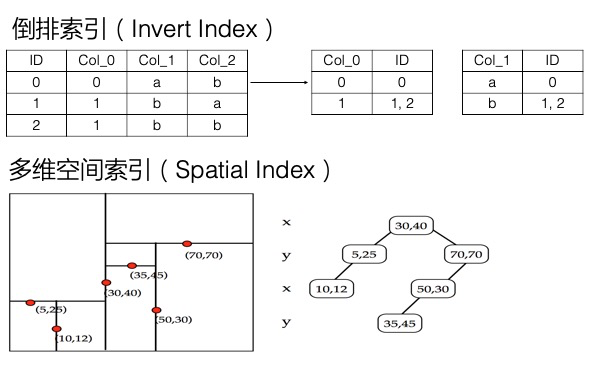
多元索引基于倒排索引和列式存儲,可以解決大數據的多維數據查詢和統計分析難題,包括非主鍵列查詢、前綴查詢、模糊查詢、多字段自由組合查詢、嵌套查詢、地理位置查詢、全文檢索、向量檢索和統計聚合(max、min、count、sum、avg、distinct_count、group_by、percentiles和histogram)等功能。
下圖展示了多元索引采用的倒排索引和列式存儲的原理以及多維空間索引結構。
多元索引的使用方式不同于MySQL等傳統數據庫的索引使用方式,無最左匹配原則的限制,使用時非常靈活。一般情況下一張表只需要創建一個多元索引即可。例如有一個學生表,包括姓名、學號、性別、年級、班級、家庭住址等列,如果要實現姓名等于張三且年級為三年級的學生、家庭住址在附近1公里內且性別為男的學生、找出三年級二班住在某小區的學生等任意條件的組合查詢,您可以創建一個多元索引實現,在創建多元索引時,將這些列添加到同一個多元索引中即可。
表格存儲為數據表提供了數據表主鍵查詢方式,還提供了二級索引(Secondary Index)和多元索引兩種加速查詢的索引結構。下表展示了三種查詢方式的區別。
查詢方式 | 原理 | 場景 |
數據表主鍵 | 數據表類似于一個巨大的Map,它的查詢能力也就類似于Map,只能通過主鍵查詢。 | 適用于可以確定完整主鍵(Key)或主鍵前綴(Key prefix)的場景。 |
二級索引 | 通過創建一張或多張索引表,使用索引表的主鍵列查詢,相當于把數據表的主鍵查詢能力擴展到了不同的列。 | 適用于能提前確定待查詢的列,待查詢列數量較少,且可以確定完整主鍵或主鍵前綴的場景。 |
多元索引 | 使用了倒排索引、BKD樹、列存等結構,具備豐富的查詢能力。 | 適用于除數據表主鍵和二級索引之外的其他所有查詢和分析場景,例如非主鍵列的條件查詢、任意列的自由組合查詢、關系查詢、全文檢索、地理位置查詢、前綴查詢、模糊查詢、嵌套結構查詢、Null值查詢、統計聚合等。 |
典型場景
多元索引可廣泛應用于各類應用系統中進行數據查詢與分析。多元索引的實際應用場景包括但不限于下表的樣例場景。
應用系統 | 樣例場景 |
電商平臺 | 在電商平臺中使用多元索引實現商品的分類、屬性篩選等功能,方便用戶進行快速的商品搜索和篩選。 |
社交應用 | 在社交網絡中使用多元索引實現用戶的關注關系、好友關系等查詢以及根據用戶的興趣標簽進行推薦和匹配。 |
日志分析 | 在日志分析場景中使用多元索引進行日志的關鍵字搜索、按照時間范圍查詢等操作,用于快速定位問題和分析日志數據。 |
物聯網數據分析 | 在物聯網場景中使用多元索引進行設備數據的查詢和分析,例如按照設備類型、地理位置等進行篩選和統計。 |
應用性能監控 | 在應用性能監控中使用多元索引進行指標數據的聚合和查詢,例如按照時間范圍、應用名稱等進行篩選和匯總。 |
地理位置服務 | 在地理位置服務中使用多元索引進行地理位置的查詢和附近搜索,用于提供附近的店鋪、景點、服務等信息。 |
文本搜索引擎 | 在文本搜索引擎中使用多元索引進行全文檢索和相關性排序,用于快速搜索和查找文檔、文章等信息。 |
核心功能
多元索引的核心功能主要包括:
數據庫查詢加速:
任意列查詢(包括主鍵列和非主鍵列)
多字段自由組合查詢
地理位置查詢
And、Or、Not和Null等查詢
In 查詢
模糊查詢(WildcardQuery、PrefixQuery、SuffixQuery)
嵌套查詢(NestedQuery)
排序
翻頁
統計聚合(Max、Min、Sum、Avg、Count、DistinctCount、Percentile、Histogram、GroupBy等)
全文檢索
向量檢索
數據快速篩選
更多信息,請參見多元索引功能。
容災能力
多元索引在具備同城容災的區域默認提供同城冗余的容災能力,會將數據同時存儲到多個不同的可用區,在單可用區遇到斷電、斷網或者火災等各種故障時均不會影響讀寫可用性,保障數據的正常讀寫服務。當前多元索引支持同城冗余的區域包括華北2(北京)、華東2(上海)、華東1(杭州)、華南1(深圳)、華北3(張家口)、華北6(烏蘭察布)、中國香港、日本(東京)、印度尼西亞(雅加達)、新加坡、德國(法蘭克福)等。
在上述支持同城冗余的區域內,多元索引已經完成所有存量索引的同城冗余升級,當前存量索引和未來新建索引都默認支持同城冗余。更多信息,請參見同城冗余。
使用限制
更多信息,請參見多元索引限制。
注意事項
使用多元索引時,無需為數據表設置預定義列。
適用模型
多元索引只適用于寬表模型。
索引同步
用戶為數據表創建了多元索引后,當在數據表中寫入數據時,數據會先寫入數據表中,數據寫成功后會立即返回用戶寫成功,同時另一個異步線程會從數據表中讀取寫入的數據然后寫入到多元索引,采用異步方式創建多元索引不會降低表格存儲的寫入能力。
目前多元索引的延遲大部分在3秒以內,通過表格存儲控制臺可以實時查看多元索引創建的延遲情況。
數據生命周期(TTL)
如果數據表無UpdateRow更新寫入操作,則您可以使用多元索引TTL。更多信息,請參見生命周期管理。
當只需要保留一段時間內的數據且時間字段不需要更新時,您可以通過按時間分表的方法實現數據生命周期功能。按時間分表的原理、原則和優點請參見下表說明。
維度
按時間分表
原理
按照固定時間,例如“日”、“周”、“月”或者“年”分表,并為每個表建立一個多元索引,根據需要保留所需時間的數據表。
例如當數據需要保留6個月時,可以將每個月的數據保存在一張數據表中,例如table_1、table_2、table_3、table_4、table_5、table_6,并為每個數據表創建一個多元索引,每個數據表和多元索引中只會保存一個月的數據,只需要每個月把6個月前的數據表刪除即可。
當使用多元索引查詢數據時,如果時間范圍在某個表中,只需要查詢對應表;如果時間范圍在多個表中,需要對涉及的數據表均查詢一次,再將查詢結果合并。
原則
單表(單索引)大小不超過500億行,當單表(單索引)大小不超過200億行時,多元索引的查詢性能最好。
優點
通過保留數據表的個數調節數據存儲時長。
查詢性能和數據量成正比,分表后每個表的數據大小有上限,查詢性能更好,避免查詢延遲太大或者超時。
數據多版本
多元索引不支持數據多版本,即不能對設置了數據多版本的數據表創建多元索引。
當在單版本中每次寫入數據時自定義了timestamp,且先寫入版本號較大的數據,后寫入版本號較小的數據,此時先寫入的版本號較大的數據可能會被后寫入的版本號較小的數據覆蓋。
Search和ParallelScan請求的結果數據中不一定包括timestamp屬性。
接口說明
多元索引提供了多元索引管理接口和查詢接口。其中查詢接口包括通用查詢接口(Search)和數據導出接口(ParallelScan),兩種查詢接口的功能大部分相同,但是ParallelScan接口為了提高某些方面的性能和吞吐能力舍棄了部分功能。
分類 | 接口 | 描述 |
管控接口 | 創建一個多元索引。 | |
獲取多元索引的詳細描述信息。 | ||
列出多元索引的列表。 | ||
刪除某個多元索引。 | ||
查詢接口 | Search | 全功能查詢接口,支持多元索引的所有功能點,包括所有的查詢功能以及排序、統計聚合等分析能力,其結果會按照指定的順序返回。
|
多并發數據導出接口,只包括所有的查詢功能,舍棄了排序、統計聚合等分析能力,能將命中的數據以更快的速度全部返回。 相對于Search接口,ParallelScan可以提供更好的性能,單并發時性能(吞吐能力)是Search接口的5倍。
多并發導出數據時,您還需要通過ComputeSplits接口獲取當前ParallelScan單個請求的最大并發數。 |
使用流程

步驟 | 操作 | 說明 |
1 | 在數據表上創建一個多元索引后,您可以根據多元索引中建立索引的字段來查詢數據表中的數據。 | |
2 | 使用多元索引查詢數據 | 多元索引提供了全匹配查詢、匹配查詢、短語匹配查詢、精確查詢、多詞精確查詢、前綴查詢、范圍查詢、通配符查詢、多條件組合查詢、嵌套類型查詢、地理距離查詢、地理長方形范圍查詢、地理多邊形范圍查詢、列存在性查詢、折疊(去重)等數據查詢功能,請根據實際查詢場景選擇。 使用多元索引查詢數據時支持通過配置分詞指定匹配詞的切分方式以及對滿足條件的數據進行排序和翻頁。更多信息,請參見分詞和排序和翻頁。 |
3 | 如果要分析表中數據,您可以使用統計聚合功能實現求最小值、求最大值、求和、求平均值、統計行數、去重統計行數、百分位統計、按字段值分組、按范圍分組、按地理位置分組、按過濾條件分組、直方圖統計、日期直方圖統計等數據分析功能。 | |
4 | 當使用場景中不關心整個結果集的順序時,您可以使用并發導出數據功能以更快的速度將命中的數據全部返回。 |
使用方式
您可以通過控制臺、命令行工具或者SDK使用多元索引。
計費說明
表格存儲支持VCU模式(原預留模式)和CU模式(原按量模式)兩種計費模式,請根據所用的實例模型參考相應計費模式了解多元索引計費信息。更多信息,請參見計費概述。
VCU模式(原預留模式):計費項包括計算能力、數據存儲量和外網下行流量,其中數據存儲量包括高性能存儲、容量型存儲和多元索引存儲。
使用多元索引時,索引數據量占用的存儲空間為多元索引存儲,通過多元索引查詢與分析數據會消耗計算資源。
CU模式(原按量模式):多元索引計費項包括讀吞吐量、數據存儲量和外網下行流量,其中讀吞吐量包括預留讀吞吐量和按量讀吞吐量。更多信息,請參見多元索引計量計費。
常見問題
相關文檔
如果要使用SQL查詢與分析數據,您可以使用表格存儲的SQL查詢功能實現。更多信息,請參見SQL查詢。
說明您也可以通過MaxCompute、Spark、Hive或者HadoopMR、函數計算、Flink等計算引擎分析表格存儲中的數據。更多信息,請參見計算與分析概述。
基于多元索引可以實現搭建億量級店鋪搜索系統等方案。更多方案介紹,請參見多元索引實踐。
表格存儲控制臺提供了多元索引相關電商訂單、店鋪搜索、地理圍欄和智能元數據的場景Demo。具體樣例請參見場景Demo。