Spark是一個通用的大數據計算引擎。本文為您介紹如何在Zeppelin中使用Spark。
背景信息
Zeppelin支持Spark的4種主流語言,包括Scala、PySpark、R和SQL。Zeppelin中所有語言在同一個Spark Application里,即共享一個SparkContext和SparkSession。例如,您在Scala里注冊的table和UDF是可以被其他語言使用的。
Spark解釋器的基本架構如下圖所示: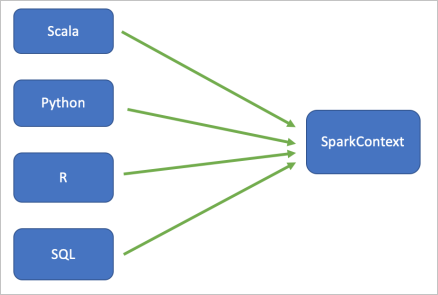
Zeppelin支持Spark,您可以在Zeppelin里使用Spark的所有功能。
Scala(%spark)
以%spark開頭的就是Scala代碼的段落(Paragraph)。因為Zeppelin已經為您內置了Scala的SparkContext (sc)和SparkSession(spark)變量,所以您無需再創建SparkContext或者SparkSession。
代碼示例如下:
%spark
val sum = sc.range(1,10).sum()
println("Sum = " + sum)Code Completion
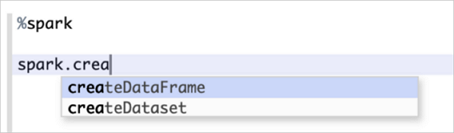
Zeppelin里的Scala Shell是支持Code Completion的,按Tab鍵即可顯示當前環境下的候選方法名,如下圖所示:
ZeppelinContext
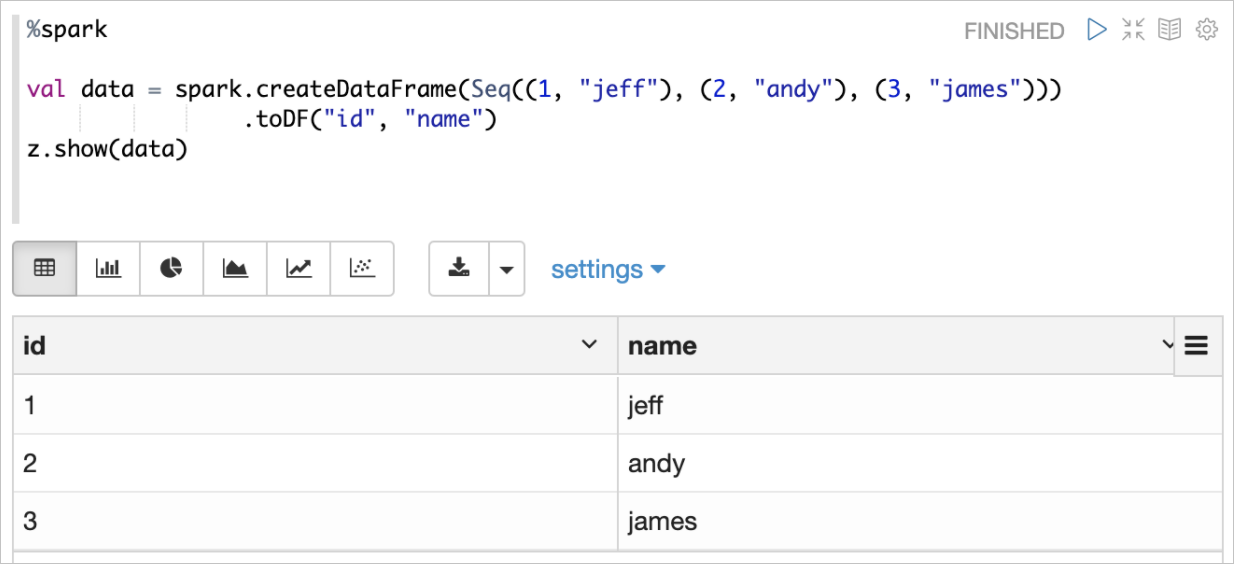
ZeppelinContext(變量名為z)是在Spark Scala Shell環境下創建的一個提供一些高級用法的Class。比較實用的方法是z.show。使用z.show展示DataFrame示例如下所示:
PySpark(%spark.pyspark)
以%spark.pyspark開頭的就是PySpark代碼的段落(Paragraph)。因為Zeppelin已經為您內置了PySpark的SparkContext (sc)和SparkSession(spark)變量,所以您無需再創建SparkContext或者SparkSession。
代碼示例如下:
%spark.pyspark
sum = sc.range(1,10).sum()
print("Sum = " + str(sum))SparkR(%spark.r)
如果您需要使用SparkR,那么請確保您的EMR集群里安裝了R語言以及knitr包(需要在每個NodeManager節點上安裝,因為數據開發中默認配置的是Yarn-Cluster模式,Driver有可能運行在任意一個NodeManager節點上)。
安裝命令如下:
執行如下命令安裝R語言。
sudo yum install epel-release sudo yum install R在R里面安裝knitr包。
install.packages("knitr")
示例如下:
使用SparkR創建一個DataFrame,并注冊為一張table。

使用Spark SQL查詢注冊的table。
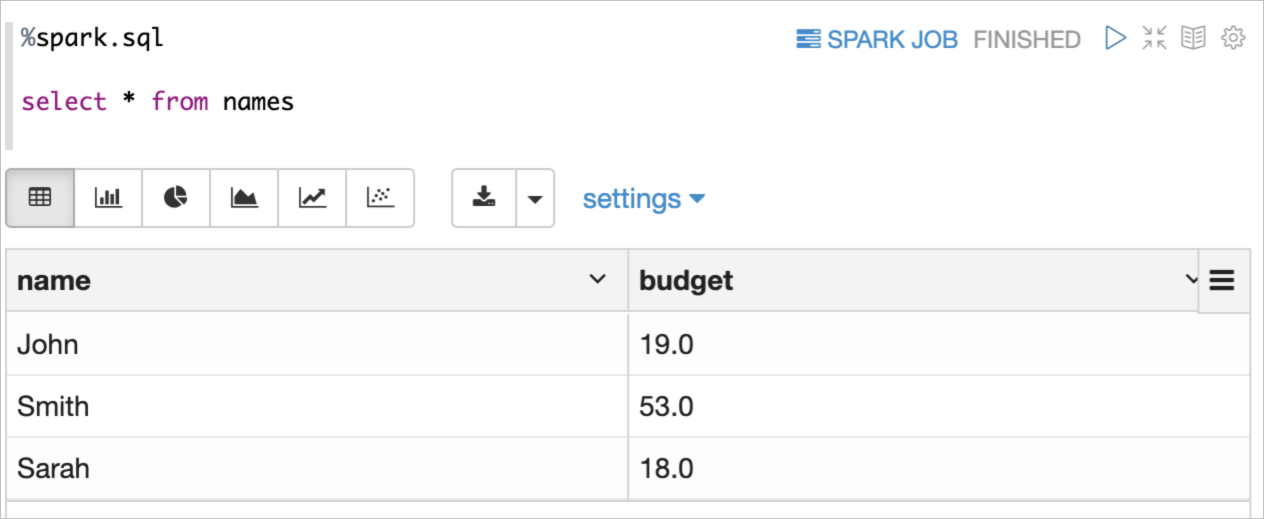
SQL(%spark.sql)
以%spark.sql開頭的就是Spark SQL的段落(Paragraph)。您可以運行所有Spark支持的SQL語句,通過Zeppelin可視化展示,如下圖所示: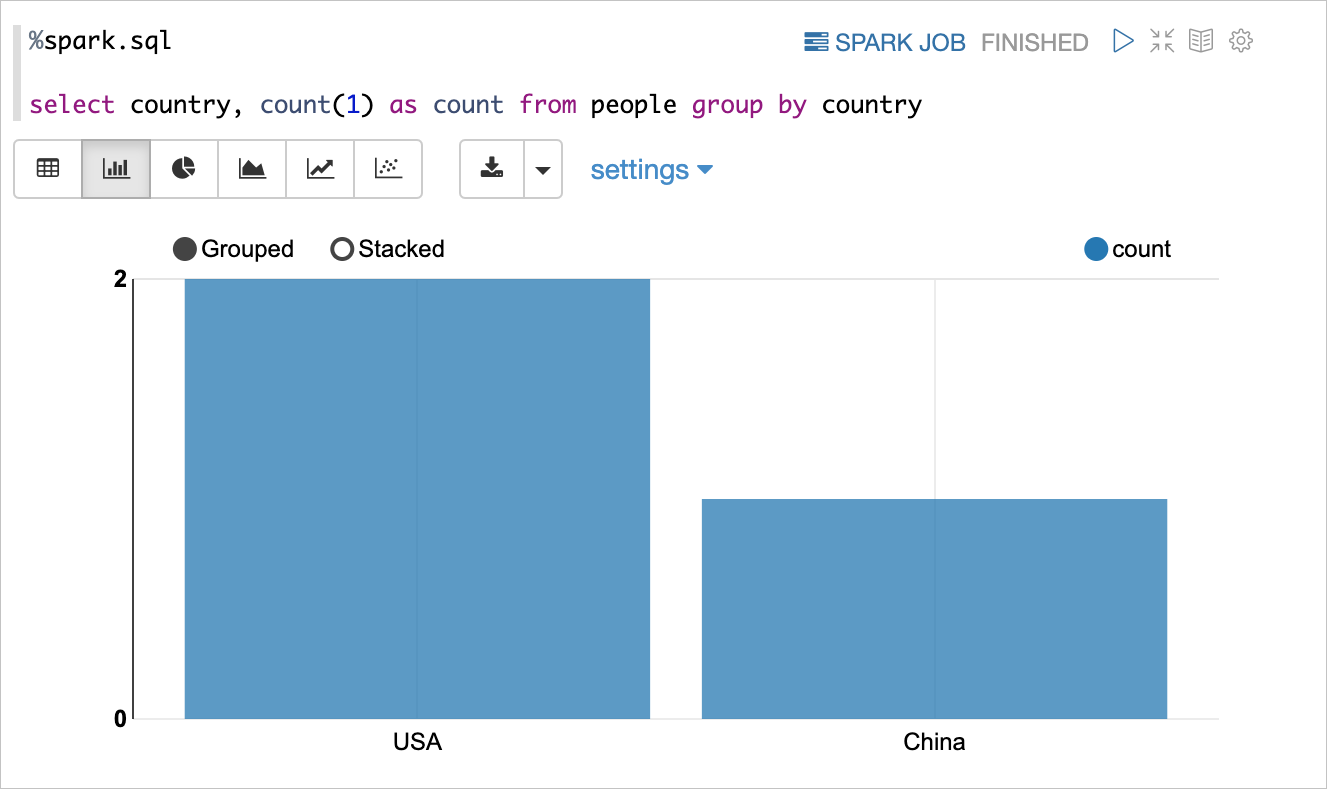
Zeppelin的Spark SQL解釋器和其他Spark解釋器(PySpark、SparkR和Spark解釋器)共享SparkContext和SparkSession,即用其他Spark解釋器注冊的表也可以使用Spark SQL解釋器進行訪問。例如:
%spark
case class People(name: String, age: Int)
var df = spark.createDataFrame(List(People("jeff", 23), People("andy", 20)))
df.createOrReplaceTempView("people")%spark.sql
select * from peopleSpark SQL解釋器還支持并行運行,即支持同時運行多個SQL。另外,由于Spark SQL本身的特性,Spark SQL Statement支持大多數Hive SQL語法。Spark集成Hive后,通常場景下,您可以使用Spark SQL解釋器訪問Hive表來進行更高效的分析計算,數據開發里的Spark解釋器默認已經開啟了Hive。
配置Spark
在阿里云EMR的數據開發里,Spark解釋器配置的是Isolated Per Note模式,也就是說每個Note都有一個獨立的Spark Application(每個Note對應一個Yarn App,Zeppelin里使用的是Yarn-Cluster模式)。對于每一個Spark Application,您可以在%spark.conf里配置所有Spark相關的配置選項,具體配置選項,請參見Spark Configuration。
代碼示例如下:
因為Spark只支持在啟動Spark Application之前配置屬性,所以%spark.conf必須在運行Spark代碼之前運行。
如果您在啟動Spark Application之后想修改配置(例如,修改Driver Memory),則您必須重啟當前Note的Spark解釋器。重啟步驟如下:
單擊
 圖標。
圖標。
單擊
 圖標。
圖標。
重新運行%spark.conf段落。
EMR數據開發中的Spark解釋器默認配置如下:
Yarn-Cluster模式。
啟用Hive。
Driver內存1 GB,Executor內存1 GB。
啟用Dynamic Executor Allocation。
初始化Executor 1個,最大Executor 10個,更多配置信息,請參見Spark Configuration。
第三方依賴
Spark作業經常會有第三方依賴。標準的Spark通常使用以下3種配置:
spark.jars
spark.jars可以用來指定JAR文件,多個JAR包可以用逗號(,)隔開。您可以把JAR包放在OSS上,也可以放在目標EMR集群的HDFS上。建議您放在OSS上,以便于您的JAR包可以被多個EMR集群共享,即使切換集群也不用更改配置。
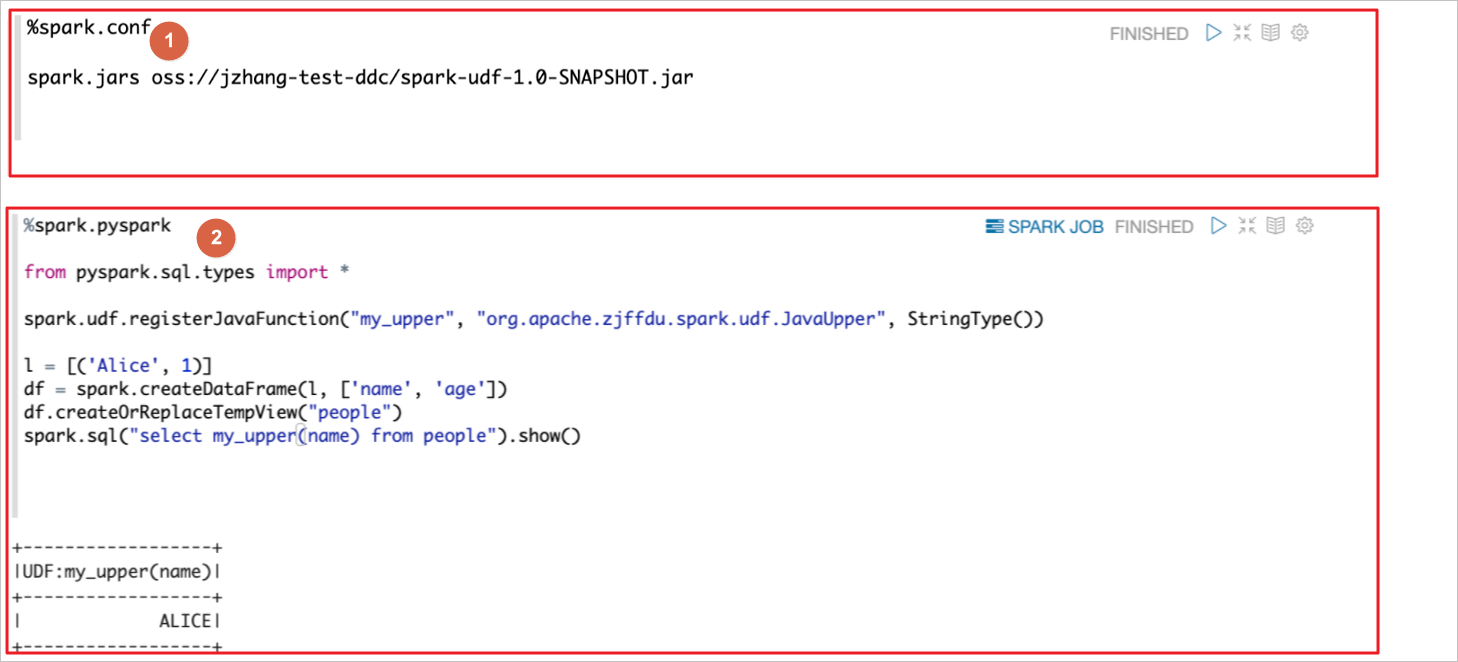
如下圖示例,段落①使用%spark.conf指定OSS上的JAR,這個JAR里寫了一個Java UDF,段落②使用PySpark注冊Java UDF,然后在SQL中使用Java UDF。
spark.jars.packages
spark.jars.packages可以用Package的形式來指定依賴包,Spark會動態下載這些Package到ClassPath里,多個Package以逗號(,)分隔。
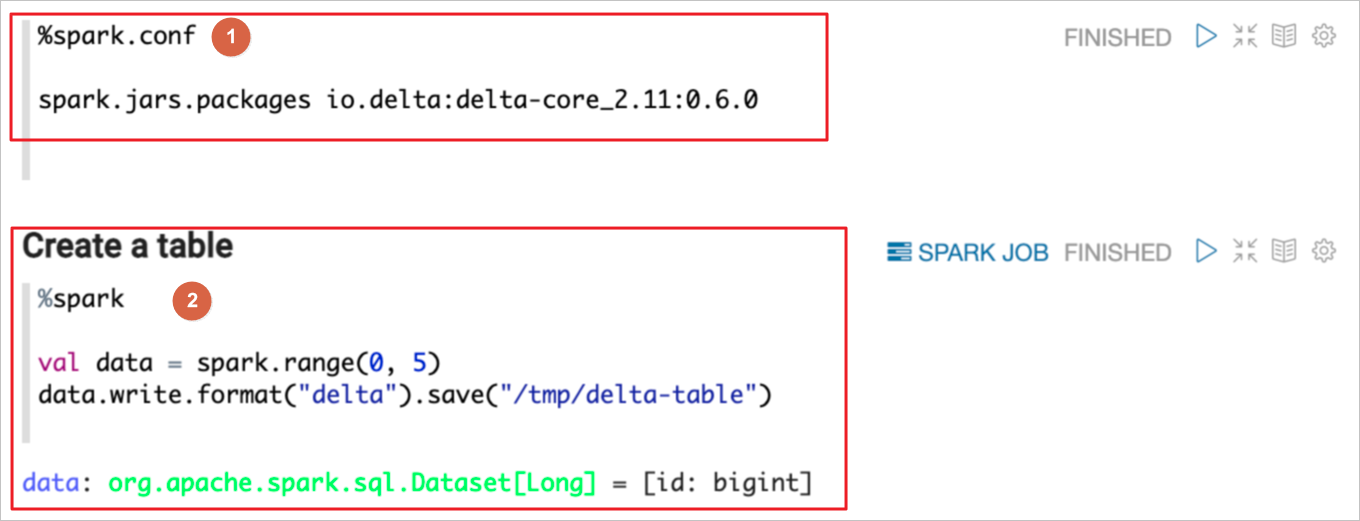
如下圖示例,段落①指定delta包,段落②使用這個delta包。
spark.files
spark.files用來指定File文件,多個File文件以逗號(,)分隔。
內置教程
EMR數據開發集群自帶了很多Spark教程,詳細信息請在如下圖頁面查看。