本文介紹阿里云E-MapReduce如何訪問Zeppelin。您可以通過訪問Zeppelin,進行大數據可視化分析。
前提條件
已創建集群,并選擇了Zeppelin服務。
在集群安全組中打開8080端口。
已添加本文示例所需的服務,例如,Presto、Flink和Impala。
訪問Zeppelin
進入集群詳情頁面。
在頂部菜單欄處,根據實際情況選擇地域和資源組。
單擊上方的集群管理頁簽。
在集群管理頁面,單擊相應集群所在行的詳情。
在左側導航欄,單擊訪問鏈接與端口。
單擊Zeppelin所在行的鏈接。
您可以直接訪問Web UI頁面。
示例
以下內容只適用于EMR-3.33.0及之后版本和EMR-4.6.0及之后版本:
如何使用Spark
在Zeppelin頁面,單擊Create new note。
在Create new note對話框,輸入Note Name,選擇Default Interpreter為spark。
單擊create。
在Zeppelin的Notebook頁面,您可以執行以下命令。
您無需配置,EMR里的Zeppelin中已經配置了Spark Interpreter。Spark默認執行模式是Yarn-cluster。支持以下三種代碼方式:
Spark Scala
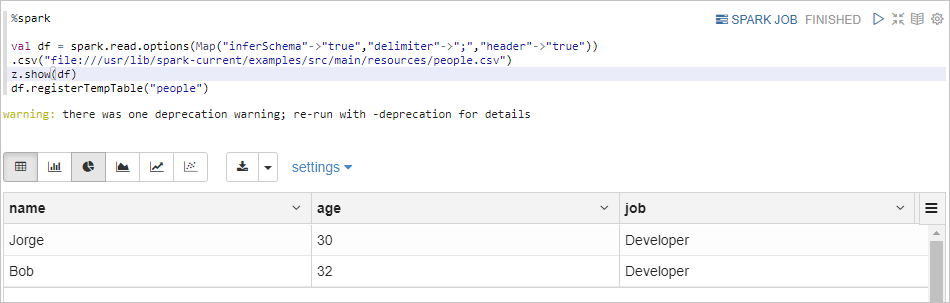
%spark表示執行Spark Scala代碼。%spark val df = spark.read.options(Map("inferSchema"->"true","delimiter"->";","header"->"true")) .csv("file:///usr/lib/spark-current/examples/src/main/resources/people.csv") z.show(df) df.registerTempTable("people")返回信息如下所示。
PySpark
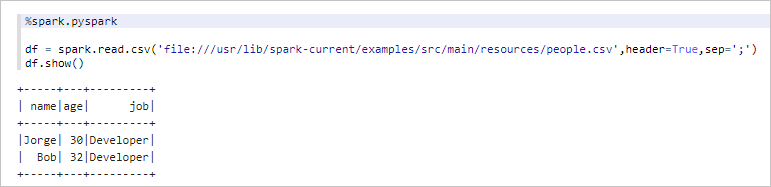
%spark.pyspark表示執行PySpark代碼。%spark.pyspark df = spark.read.csv('file:///usr/lib/spark-current/examples/src/main/resources/people.csv',header=True,sep=';') df.show()返回信息如下所示。
Spark SQL
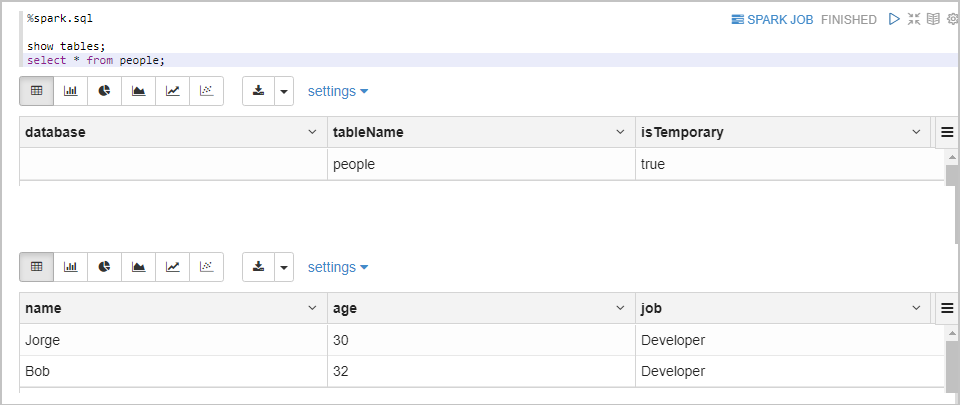
%spark.sql表示執行Spark SQL代碼。%spark.sql show tables; select * from people;返回信息如下所示。
如何使用Flink
在Zeppelin頁面,單擊Create new note。
在Create new note對話框,輸入Note Name,選擇Default Interpreter為flink。
單擊create。
在Zeppelin的Notebook頁面,您可以執行以下命令。
您無需配置,EMR里的Zeppelin已經為您配置了Flink Interpreter。支持以下三種代碼方式:
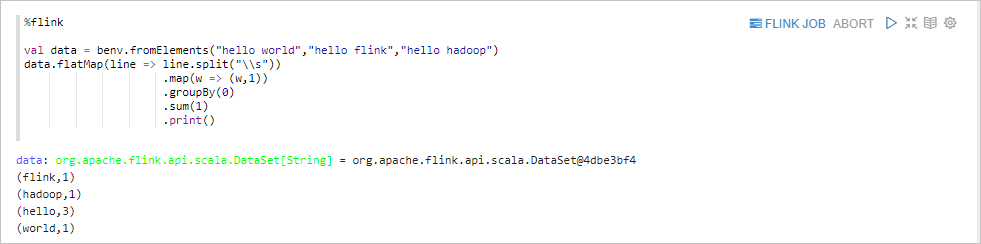
Flink Scala
%flink表示執行Flink Scala代碼。%flink val data = benv.fromElements("hello world","hello flink","hello hadoop") data.flatMap(line => line.split("\\s")) .map(w => (w,1)) .groupBy(0) .sum(1) .print()返回信息如下所示。
PyFlink
%flink.pyflink表示執行PyFlink代碼。
Flink SQL
%flink.ssql表示執行Flink SQL代碼。在運行下面的示例前,需要先運行下面的代碼以構建一個模擬用戶日志的數據。
%flink import org.apache.flink.streaming.api.functions.source.SourceFunction import org.apache.flink.table.api.TableEnvironment import org.apache.flink.streaming.api.TimeCharacteristic import org.apache.flink.streaming.api.checkpoint.ListCheckpointed import org.apache.flink.runtime.state.filesystem.FsStateBackend import java.util.Collections import scala.collection.JavaConversions._ senv.setStreamTimeCharacteristic(TimeCharacteristic.EventTime) senv.enableCheckpointing(5000) senv.setStateBackend(new FsStateBackend("file:///tmp/flink/checkpoints")); val data = senv.addSource(new SourceFunction[(Long, String)] with ListCheckpointed[java.lang.Long] { val pages = Seq("home", "search", "search", "product", "product", "product") var count: Long = 0 var running : Boolean = true // startTime is 2020/1/1 var startTime: Long = new java.util.Date(2020 - 1900,0,1).getTime var sleepInterval = 100 override def run(ctx: SourceFunction.SourceContext[(Long, String)]): Unit = { val lock = ctx.getCheckpointLock while (count < 1000000 && running) { lock.synchronized({ ctx.collect((startTime + count * sleepInterval, pages(count.toInt % pages.size))) count += 1 Thread.sleep(sleepInterval) }) } } override def cancel(): Unit = { running = false } override def snapshotState(checkpointId: Long, timestamp: Long): java.util.List[java.lang.Long] = { Collections.singletonList(count) } override def restoreState(state: java.util.List[java.lang.Long]): Unit = { state.foreach(s => count = s) } }).assignAscendingTimestamps(_._1) stenv.registerDataStream("log", data, 'time, 'url, 'rowtime.rowtime)Zeppelin支持所有類型的Flink SQL語句,包括DDL和DML等。您還可以在Zeppelin可視化流式數據,Flink支持以下三種流式數據的可視化:
Single模式
Single模式適合當輸出結果是一行的情況,不適用圖形化的方式展現。例如下面的
Select語句。這條SQL語句只有一行數據,但這行數據會持續不斷的更新。這種模式的數據輸出格式是HTML形式,您可以用template來指定輸出模板,{i}是第i列的placeholder。%flink.ssql(type=single,parallelism=1,refreshInterval=1000,template=<h1>{1}</h1> until <h2>{0}</h2>) select max(rowtime),count(1) from log返回信息如下所示。

Update模式
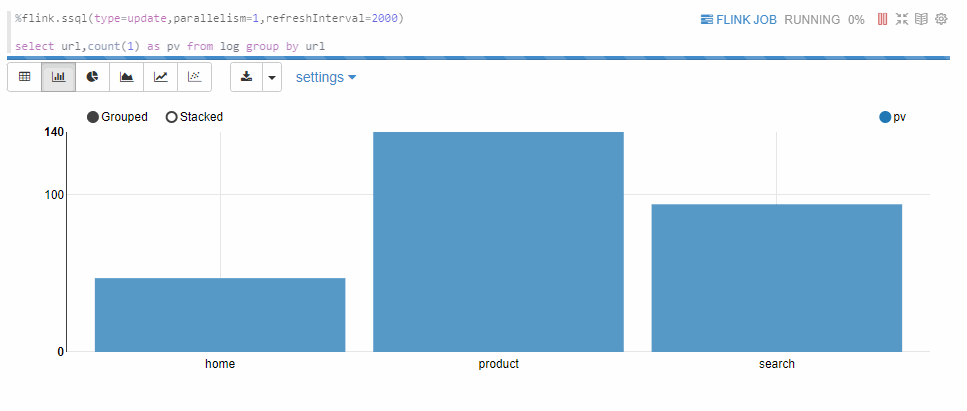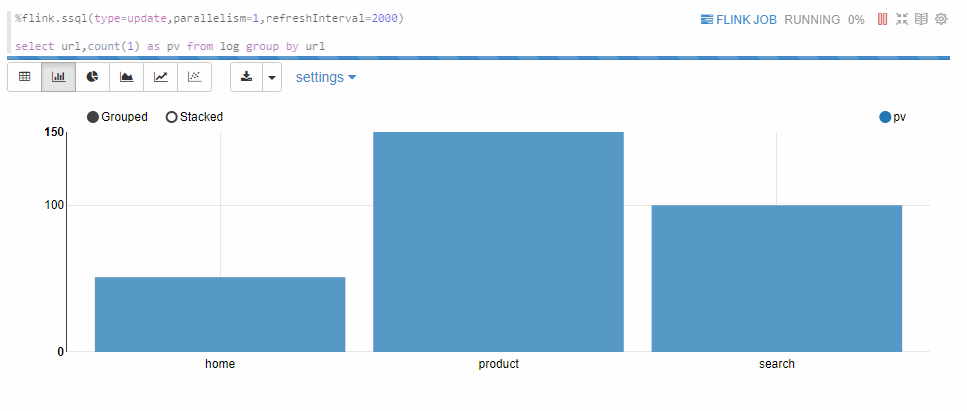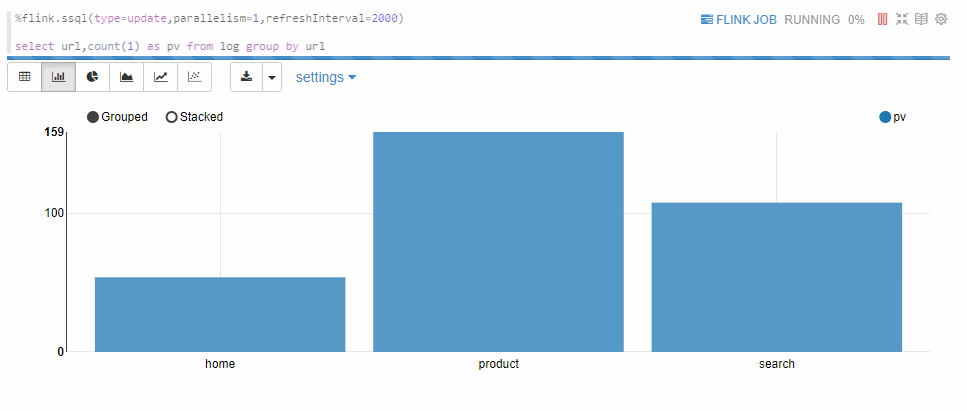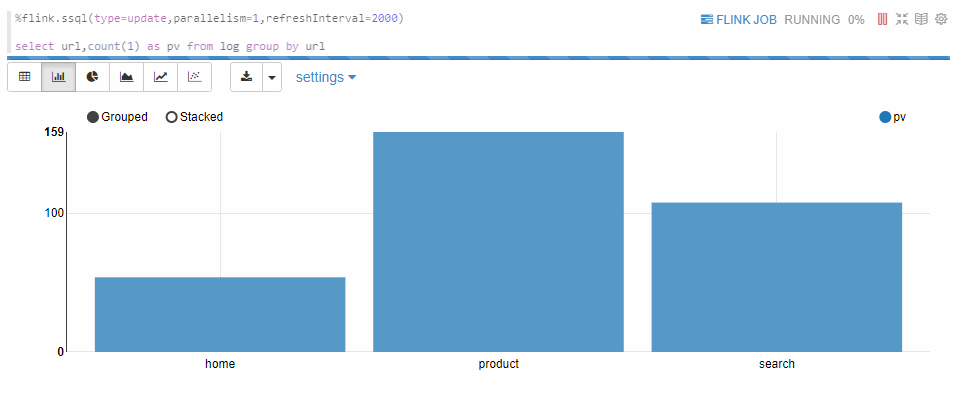
Update模式適合多行輸出的情況。例如下面的
select group by語句。此模式會定期更新這多行數據,輸出是Zeppelin的table格式,因此可以用Zeppelin自帶的可視化控件。%flink.ssql(type=update,parallelism=1,refreshInterval=2000) select url,count(1) as pv from log group by url返回信息如下所示。
Append模式
Append模式適合不斷有新數據輸出,但不會覆蓋原有數據,只會不斷append的情況。例如下面的基于窗口的
group by語句。Append模式要求第一列數據類型是TIMESTAMP,本示例的start_time是TIMESTAMP類型。%flink.ssql(type=append,parallelism=1,refreshInterval=2000,threshold=60000) select TUMBLE_START(rowtime,INTERVAL '5' SECOND) start_time,url,count(1) as pv from log group by TUMBLE(rowtime,INTERVAL '5' SECOND),url返回信息如下所示。
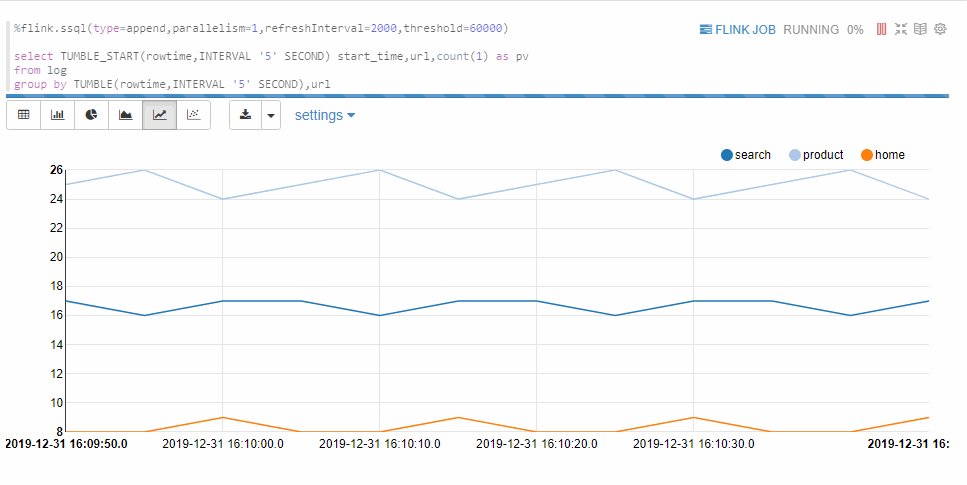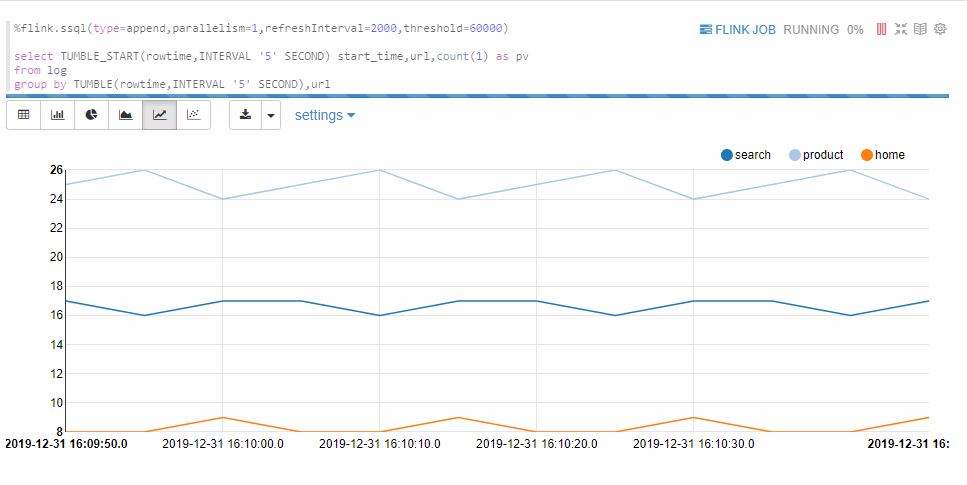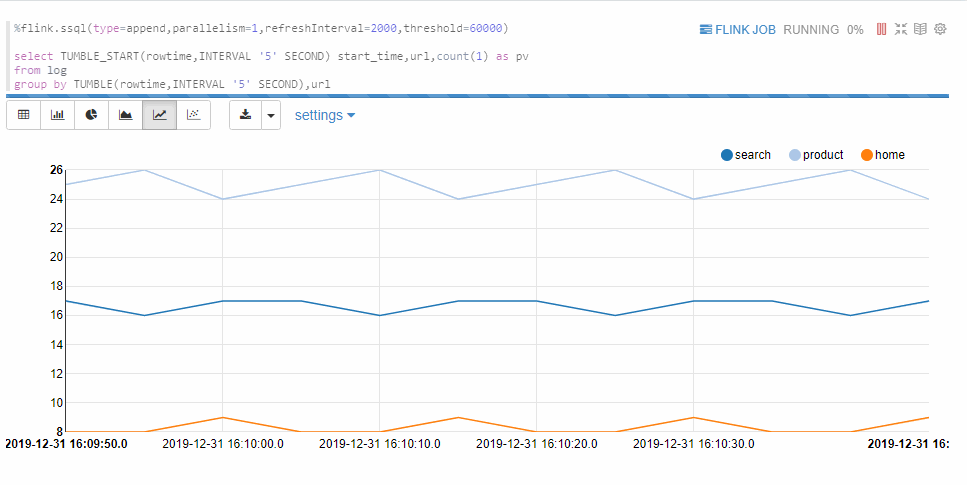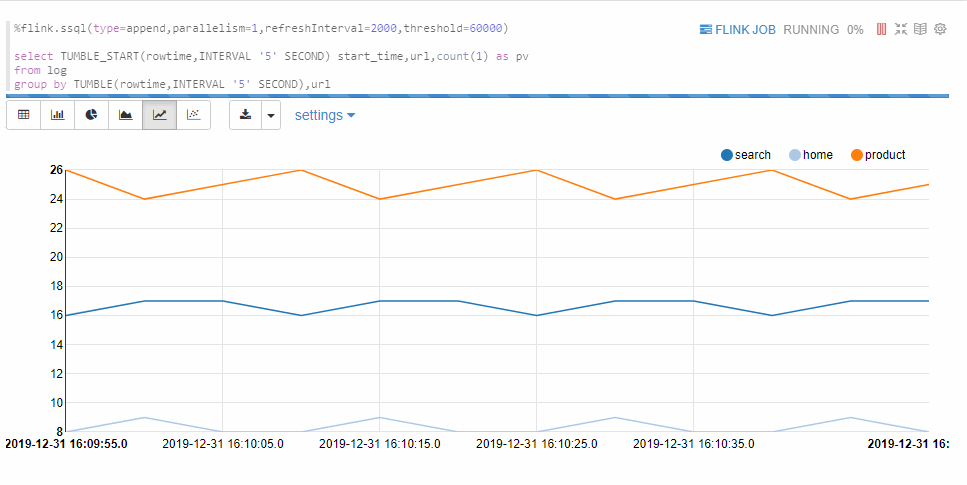
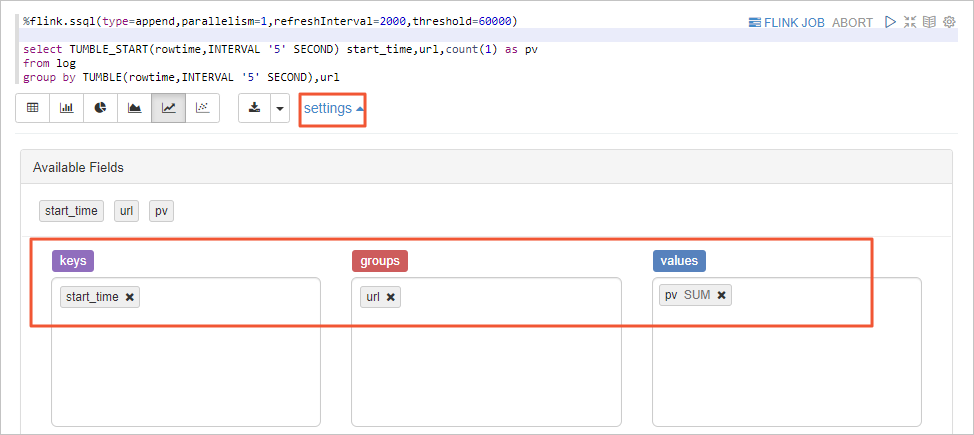
如果沒有呈現如上所示的圖表,可能是您的圖表配置不對,請按照如下圖所示配置圖表,然后運行段落。
如何使用Presto
在Zeppelin頁面,單擊Create new note。
在Create new note對話框,輸入Note Name,選擇Default Interpreter為presto。
單擊create。
在Zeppelin的Notebook頁面,您可以執行以下命令查看表信息。
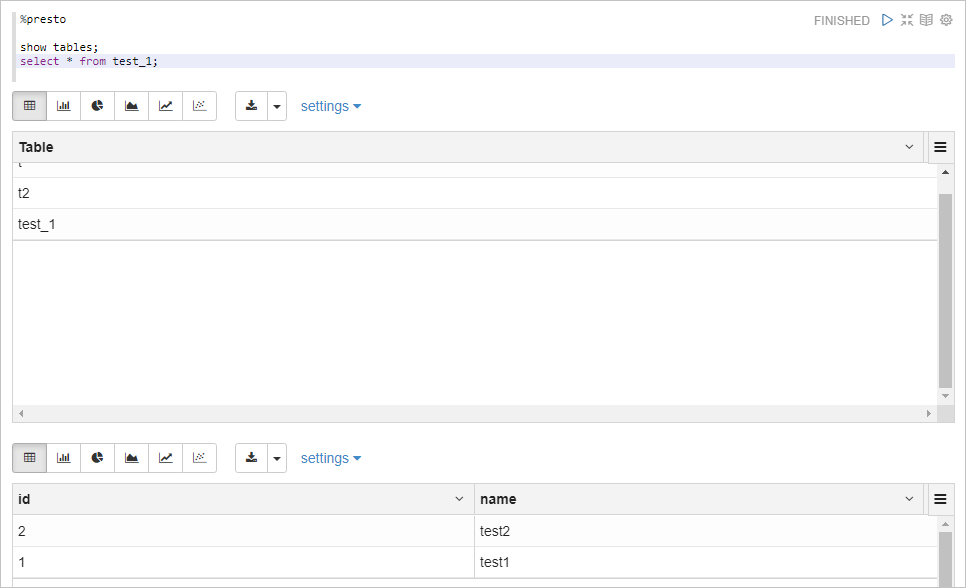
%presto表示執行Presto SQL代碼,您無需配置,Zeppelin會自動連接到EMR集群的Presto服務。%presto show tables; select * from test_1;返回信息如下所示。
如何使用Impala
在Zeppelin頁面,單擊Create new note。
在Create new note對話框,輸入Note Name,選擇Default Interpreter為impala。
單擊create。
在Zeppelin的Notebook頁面,您可以執行以下命令查看表信息。
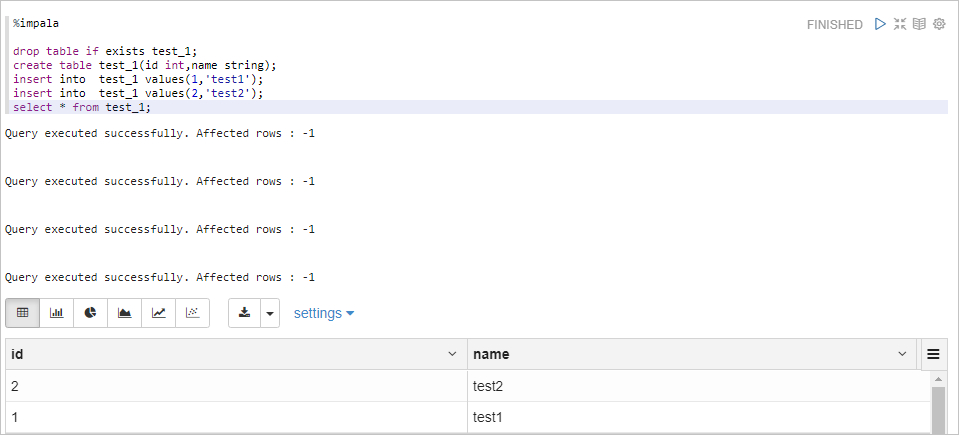
%impala表示執行Impala SQL代碼,您無需配置,Zeppelin會自動連接到EMR集群的Impala服務。%impala drop table if exists test_1; create table test_1(id int,name string); insert into test_1 values(1,'test1'); insert into test_1 values(2,'test2'); select * from test_1;返回信息如下所示。
如何使用Hive
在Zeppelin頁面,單擊Create new note。
在Create new note對話框,輸入Note Name,選擇Default Interpreter為hive。
單擊create。
在Zeppelin的Notebook頁面,您可以執行以下命令查看表信息。
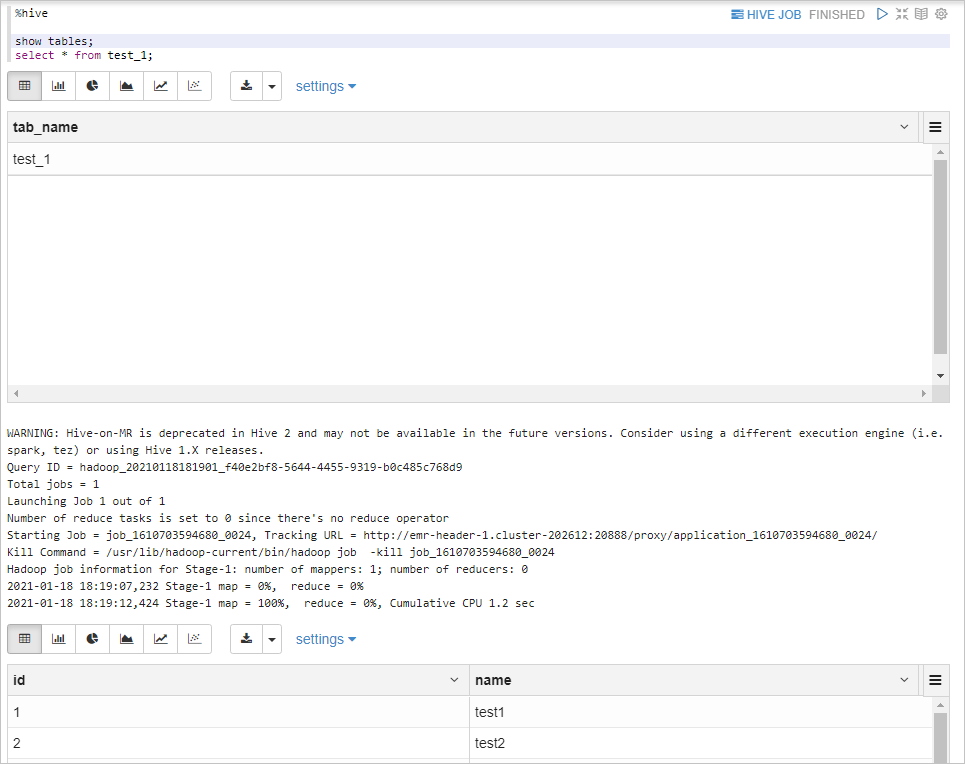
%hive表示執行Hive SQL代碼,您無需配置,Zeppelin會自動連接到EMR集群的Hive Thrift Server服務。%hive show tables; select * from test_1;返回信息如下所示。