EMR Serverless Spark內置了基于Spark DataSource V2的MaxCompute DataSource,只需在開發時添加對應的配置即可連接MaxCompute。本文為您介紹在EMR Serverless Spark中實現MaxCompute的讀取與寫入操作。
背景信息
大數據計算服務MaxCompute(原名ODPS)是一種快速、完全托管的EB級數據倉庫解決方案,致力于批量結構化數據的存儲和計算,提供海量數據倉庫的解決方案及分析建模服務。MaxCompute的詳情請參見什么是MaxCompute。
前提條件
已創建EMR Serverless Spark工作空間,詳情請參見創建工作空間。
已創建MaxCompute項目,詳情請參見創建MaxCompute項目。
操作流程
步驟一:創建會話連接MaxCompute
您可以創建SQL會話,或者Notebook會話來連接MaxCompute。關于會話更多介紹,請參見會話管理。
創建SQL會話連接MaxCompute
進入會話管理頁面。
在左側導航欄,選擇。
在Spark頁面,單擊目標工作空間名稱。
在EMR Serverless Spark頁面,單擊左側導航欄中的會話管理。
在SQL會話頁面,單擊創建SQL會話。
在創建SQL會話頁面,配置以下信息,單擊創建。
參數
說明
名稱
自定義SQL會話的名稱。例如,mc_sql_compute。
Spark配置
填寫Spark配置信息,以連接阿里云MaxCompute。
spark.sql.catalog.odps org.apache.spark.sql.execution.datasources.v2.odps.OdpsTableCatalog spark.sql.extensions org.apache.spark.sql.execution.datasources.v2.odps.extension.OdpsExtensions spark.sql.catalog.odps.enableNamespaceSchema true spark.sql.sources.partitionOverwriteMode dynamic spark.hadoop.odps.project.name <project_name> spark.hadoop.odps.end.point http://service.cn-hangzhou-vpc.maxcompute.aliyun-inc.com/api spark.hadoop.odps.access.id <accessId> spark.hadoop.odps.access.key <accessKey>請根據您的實際情況替換以下信息:
<project_name>:您的MaxCompute項目名稱。http://service.cn-hangzhou-vpc.maxcompute.aliyun-inc.com/api:您的MaxCompute的Endpoint信息,詳情請參見Endpoint。<accessId>:訪問MaxCompute服務所使用阿里云賬號的AccessKey ID。<accessKey>:訪問MaxCompute服務所使用阿里云賬號的AccessKey Secret。
創建Notebook會話連接MaxCompute
進入Notebook會話頁面。
在左側導航欄,選擇。
在Spark頁面,單擊目標工作空間名稱。
在EMR Serverless Spark頁面,選擇左側導航欄中的會話管理。
單擊Notebook會話頁簽。
單擊創建Notebook會話。
在創建Notebook會話頁面,配置以下信息,單擊創建。
參數
說明
名稱
自定義Notebook會話的名稱。例如,mc_notebook_compute。
Spark配置
填寫Spark配置信息,以連接阿里云MaxCompute。
spark.sql.catalog.odps org.apache.spark.sql.execution.datasources.v2.odps.OdpsTableCatalog spark.sql.extensions org.apache.spark.sql.execution.datasources.v2.odps.extension.OdpsExtensions spark.sql.catalog.odps.enableNamespaceSchema true spark.sql.sources.partitionOverwriteMode dynamic spark.hadoop.odps.project.name <project_name> spark.hadoop.odps.end.point http://service.cn-hangzhou-vpc.maxcompute.aliyun-inc.com/api spark.hadoop.odps.access.id <accessId> spark.hadoop.odps.access.key <accessKey>請根據您的實際情況替換以下信息:
<project_name>:您的MaxCompute項目名稱。http://service.cn-hangzhou-vpc.maxcompute.aliyun-inc.com/api:您的MaxCompute的Endpoint信息,詳情請參見Endpoint。<accessId>:訪問MaxCompute服務所使用阿里云賬號的AccessKey ID。<accessKey>:訪問MaxCompute服務所使用阿里云賬號的AccessKey Secret。
步驟二:查詢或向MaxCompute中寫數據
創建SparkSQL或Notebook向MaxCompute中寫數據
創建SparkSQL向MaxCompute中寫數據
在EMR Serverless Spark頁面,單擊左側導航欄中的數據開發。
在開發目錄頁簽下,單擊新建。
新建SparkSQL。
在彈出的對話框中,輸入名稱(例如,mc_load_task),類型使用默認的SparkSQL,然后單擊確定。
拷貝如下代碼到新增的Spark SQL頁簽(mc_load_task)中。
CREATE TABLE odps.default.customer_total_return AS ( SELECT sr_customer_sk AS ctr_customer_sk, sr_store_sk AS ctr_store_sk, sum(sr_return_amt) AS ctr_total_return FROM odps.bigdata_public_dataset.tpcds_10g.store_returns, odps.bigdata_public_dataset.tpcds_10g.date_dim WHERE sr_returned_date_sk = d_date_sk AND d_year = 2000 GROUP BY sr_customer_sk, sr_store_sk ); SELECT * FROM odps.default.customer_total_return;在數據庫下拉列表中選擇一個數據庫,在Compute下拉列表中選擇步驟一:創建會話連接MaxCompute中創建的SQL會話(mc_sql_compute)。
單擊運行,執行創建的SparkSQL。
查詢執行成功后,在運行結果中輸出了查詢結果。
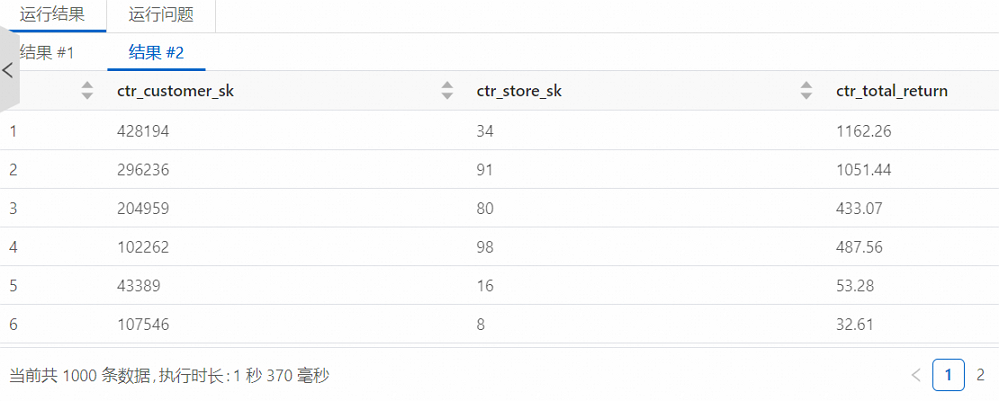
在MaxCompute控制臺查看創建的表。
登錄MaxCompute控制臺,在左上角選擇地域。
在項目管理頁面,單擊已創建項目操作列的管理。
單擊Tables頁簽。
即可在MaxCompute控制臺看到創建了一個名為
customer_total_return的新表。
創建Notebook向MaxCompute中寫數據
在EMR Serverless Spark頁面,單擊左側導航欄中的數據開發。
在開發目錄頁簽下,單擊新建。
新建Notebook。
在彈出的對話框中,輸入名稱(例如,mc_load_task),類型使用,然后單擊確定。
在會話下拉列表中選擇步驟一:創建會話連接MaxCompute中創建的并已啟動的Notebook會話(mc_notebook_compute)。
拷貝如下代碼到新增的Notebook的Python單元格中。
spark.sql(""" CREATE TABLE odps.default.customer_total_return AS ( SELECT sr_customer_sk AS ctr_customer_sk, sr_store_sk AS ctr_store_sk, sum(sr_return_amt) AS ctr_total_return FROM odps.bigdata_public_dataset.tpcds_10g.store_returns, odps.bigdata_public_dataset.tpcds_10g.date_dim WHERE sr_returned_date_sk = d_date_sk AND d_year = 2000 GROUP BY sr_customer_sk, sr_store_sk ); """) spark.sql("SELECT * FROM odps.default.customer_total_return LIMIT 10").show()單擊單元格前面的
 圖標,或者單擊運行所有單元格,執行創建的Notebook。
圖標,或者單擊運行所有單元格,執行創建的Notebook。查詢執行成功后,在運行結果中輸出了查詢結果。
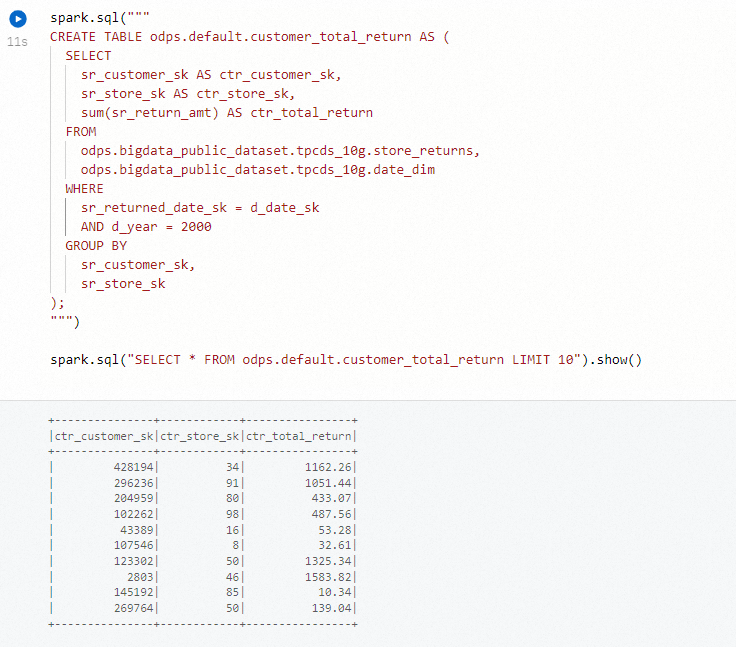
在MaxCompute控制臺查看創建的表。
登錄MaxCompute控制臺,在左上角選擇地域。
在項目管理頁面,單擊已創建項目操作列的管理。
單擊Tables頁簽。
即可在MaxCompute控制臺看到創建了一個名為
customer_total_return的新表。
創建SparkSQL或Notebook查詢MaxCompute中數據
本文以查詢MaxCompute TPC-DS公開數據集中的數據為例。
創建SparkSQL查詢MaxCompute中數據
在EMR Serverless Spark頁面,單擊左側導航欄中的數據開發。
在開發目錄頁簽下,單擊新建。
新建SparkSQL。
在彈出的對話框中,輸入名稱(例如,mc_read_sql_task),類型使用默認的SparkSQL,然后單擊確定。
拷貝如下代碼到新增的Spark SQL頁簽(mc_read_sql_task)中。
WITH customer_total_return AS ( SELECT sr_customer_sk AS ctr_customer_sk, sr_store_sk AS ctr_store_sk, sum(sr_return_amt) AS ctr_total_return FROM odps.bigdata_public_dataset.tpcds_10g.store_returns, odps.bigdata_public_dataset.tpcds_10g.date_dim WHERE sr_returned_date_sk = d_date_sk AND d_year = 2000 GROUP BY sr_customer_sk, sr_store_sk ) SELECT c_customer_id FROM customer_total_return ctr1, odps.bigdata_public_dataset.tpcds_10g.store, odps.bigdata_public_dataset.tpcds_10g.customer WHERE ctr1.ctr_total_return > ( SELECT avg(ctr_total_return) * 1.2 FROM customer_total_return ctr2 WHERE ctr1.ctr_store_sk = ctr2.ctr_store_sk ) AND s_store_sk = ctr1.ctr_store_sk AND s_state = 'TN' AND ctr1.ctr_customer_sk = c_customer_sk ORDER BY c_customer_id LIMIT 100;在數據庫下拉列表中選擇一個數據庫,在Compute下拉列表中選擇步驟一:創建會話連接MaxCompute中創建的SQL會話(mc_sql_compute)。
單擊運行,執行創建的SparkSQL。
查詢執行成功后,在運行結果中輸出了正確的查詢結果。
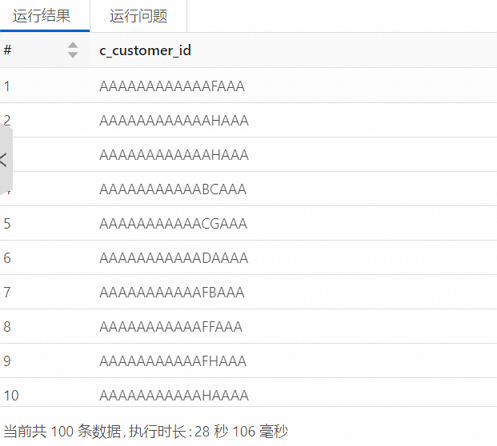
創建Notebook查詢MaxCompute中數據
在EMR Serverless Spark頁面,單擊左側導航欄中的數據開發。
在開發目錄頁簽下,單擊新建。
新建Notebook。
在彈出的對話框中,輸入名稱(例如,mc_read_notebook_task),類型使用默認的SparkSQL,然后單擊確定。
在會話下拉列表中選擇步驟一:創建會話連接MaxCompute中創建的并已啟動的Notebook會話(mc_notebook_compute)。
拷貝如下代碼到新增的Spark SQL頁簽(mc_read_notebook_task)中。
spark.sql(""" WITH customer_total_return AS ( SELECT sr_customer_sk AS ctr_customer_sk, sr_store_sk AS ctr_store_sk, sum(sr_return_amt) AS ctr_total_return FROM odps.bigdata_public_dataset.tpcds_10g.store_returns, odps.bigdata_public_dataset.tpcds_10g.date_dim WHERE sr_returned_date_sk = d_date_sk AND d_year = 2000 GROUP BY sr_customer_sk, sr_store_sk ) SELECT c_customer_id FROM customer_total_return ctr1, odps.bigdata_public_dataset.tpcds_10g.store, odps.bigdata_public_dataset.tpcds_10g.customer WHERE ctr1.ctr_total_return > ( SELECT avg(ctr_total_return) * 1.2 FROM customer_total_return ctr2 WHERE ctr1.ctr_store_sk = ctr2.ctr_store_sk ) AND s_store_sk = ctr1.ctr_store_sk AND s_state = 'TN' AND ctr1.ctr_customer_sk = c_customer_sk ORDER BY c_customer_id LIMIT 100; """).show()單擊單元格前面的
圖標,或者單擊運行所有單元格,執行創建的Notebook。查詢執行成功后,可以在單元格下方看到查詢結果。

相關文檔
本文以SparkSQL和Notebook開發類型為例,如果您想通過其他方式向MaxCompute中讀寫數據,可以參見Application開發。