通過實時計算Flink和Paimon實現(xiàn)流批一體
本文演示了使用實時計算Flink版和EMR Serverless Spark構建Paimon數(shù)據(jù)湖分析流程。該流程包括將數(shù)據(jù)寫入OSS、進行交互式查詢以及執(zhí)行離線數(shù)據(jù)Compact操作。EMR Serverless Spark完全兼容Paimon,通過內(nèi)置的DLF元數(shù)據(jù)與其他云產(chǎn)品(例如,實時計算Flink版)實現(xiàn)元數(shù)據(jù)互通,形成完整的流批一體化解決方案。它支持靈活的任務運行方式和參數(shù)配置,滿足實時分析和生產(chǎn)調(diào)度的多種需求。
背景信息
實時計算Flink版
阿里云實時計算Flink版是一種全托管Serverless的Flink云服務,是一站式開發(fā)運維管理平臺,開箱即用,計費靈活。具備作業(yè)開發(fā)、數(shù)據(jù)調(diào)試、運行與監(jiān)控、自動調(diào)優(yōu)、智能診斷等全生命周期能力。更多信息,請參見什么是阿里云實時計算Flink版。
Apache Paimon
Apache Paimon是一種統(tǒng)一的數(shù)據(jù)湖存儲格式,結合Flink和Spark構建了流批處理的實時湖倉一體架構。Paimon創(chuàng)新地將湖格式與LSM(Log-structured merge-tree)技術結合,使數(shù)據(jù)湖具備了實時流更新和完整的流處理能力。更多信息,請參見Apache Paimon。
操作流程
步驟一:通過實時計算Flink創(chuàng)建Paimon Catalog
Paimon Catalog可以方便地管理同一個warehouse目錄下的所有Paimon表,并與其它阿里云產(chǎn)品連通。創(chuàng)建并使用Paimon Catalog,詳情請參見管理Paimon Catalog。
登錄實時計算控制臺。
單擊目標工作空間操作列下的控制臺。
創(chuàng)建Paimon Catalog。
在左側導航欄,選擇。
單擊
 ,新建查詢腳本。
,新建查詢腳本。填寫SQL代碼。
Catalog完整配置如下所示。
CREATE CATALOG `paimon` WITH ( 'type' = 'paimon', 'metastore' = 'dlf', 'warehouse' = '<warehouse>', 'dlf.catalog.id' = '<dlf.catalog.id>', 'dlf.catalog.accessKeyId' = '<dlf.catalog.accessKeyId>', 'dlf.catalog.accessKeySecret' = '<dlf.catalog.accessKeySecret>', 'dlf.catalog.endpoint' = '<dlf.catalog.endpoint>', 'dlf.catalog.region' = '<dlf.catalog.region>', );配置項
說明
是否必填
備注
paimon
Paimon Catalog名稱。
是
請?zhí)顚憺樽远x的英文名。
type
Catalog類型。
是
固定值為paimon。
metastore
元數(shù)據(jù)存儲類型。
是
本文示例元數(shù)據(jù)存儲類型選擇dlf,通過DLF實現(xiàn)統(tǒng)一的元數(shù)據(jù)管理,實現(xiàn)多引擎無縫銜接。
warehouse
配置數(shù)據(jù)倉庫的實際位置。
是
請根據(jù)實際情況修改。
dlf.catalog.id
DLF數(shù)據(jù)目錄ID。
是
請在數(shù)據(jù)湖構建控制臺上查看數(shù)據(jù)目錄對應的ID,具體操作請參見數(shù)據(jù)目錄。
dlf.catalog.accessKeyId
訪問DLF服務所需的Access Key ID。
是
獲取方法請參見創(chuàng)建AccessKey。
dlf.catalog.accessKeySecret
訪問DLF服務所需的Access Key Secret。
是
獲取方法請參見創(chuàng)建AccessKey。
dlf.catalog.endpoint
DLF服務的Endpoint。
是
詳情請參見已開通的地域和訪問域名。
說明如果Flink與DLF位于同一地域,則使用VPC網(wǎng)絡Endpoint,否則使用公網(wǎng)Endpoint。
dlf.catalog.region
DLF所在區(qū)域。
是
詳情請參見已開通的地域和訪問域名。
說明請和dlf.catalog.endpoint選擇的地域保持一致。
選擇或創(chuàng)建Session集群。
單擊頁面右下角的執(zhí)行環(huán)境,選擇對應版本的Session集群(VVR 8.0.4及以上引擎版本)。如果沒有Session集群,請參見步驟一:創(chuàng)建Session集群。
選中目標代碼片段后,單擊代碼行左側的運行。
創(chuàng)建Paimon表。
在查詢腳本文本編輯區(qū)域輸入如下命令后,選中代碼后單擊運行。
CREATE TABLE IF NOT EXISTS `paimon`.`test_paimon_db`.`test_append_tbl` ( id STRING, data STRING, category INT, ts STRING, dt STRING, hh STRING ) PARTITIONED BY (dt, hh) WITH ( 'write-only' = 'true' );創(chuàng)建流作業(yè)。
新建作業(yè)。
在左側導航欄,選擇。
單擊新建。
單擊空白的流作業(yè)草稿。
單擊下一步。
在新建作業(yè)草稿對話框中,填寫作業(yè)配置信息。
作業(yè)參數(shù)
說明
文件名稱
作業(yè)的名稱。
說明作業(yè)名稱在當前項目中必須保持唯一。
存儲位置
指定該作業(yè)的存儲位置。
您還可以在現(xiàn)有文件夾右側,單擊
 圖標,新建子文件夾。
圖標,新建子文件夾。引擎版本
當前作業(yè)使用的Flink的引擎版本。引擎版本號含義、版本對應關系和生命周期重要時間點詳情請參見引擎版本介紹。
單擊創(chuàng)建。
編寫代碼。
在新建的作業(yè)草稿中,輸入以下代碼,通過datagen源源不斷生成數(shù)據(jù)寫入Paimon表中。
CREATE TEMPORARY TABLE datagen ( id string, data string, category int ) WITH ( 'connector' = 'datagen', 'rows-per-second' = '100', 'fields.category.kind' = 'random', 'fields.category.min' = '1', 'fields.category.max' = '10' ); INSERT INTO `paimon`.`test_paimon_db`.`test_append_tbl` SELECT id, data, category, cast(LOCALTIMESTAMP as string) as ts, cast(CURRENT_DATE as string) as dt, cast(hour(LOCALTIMESTAMP) as string) as hh FROM datagen;單擊部署,即可將數(shù)據(jù)發(fā)布至生產(chǎn)環(huán)境。
您可以在作業(yè)運維頁面啟動作業(yè)進入運行階段,詳情請參見作業(yè)啟動。
步驟二:通過EMR Serverless Spark創(chuàng)建SQL會話
創(chuàng)建的SQL會話用于SQL開發(fā)和查詢。有關會話的詳細介紹,請參見會話管理。
進入會話管理頁面。
在左側導航欄,選擇。
在Spark頁面,單擊目標工作空間名稱。
在EMR Serverless Spark頁面,單擊左側導航欄中的會話管理。
創(chuàng)建SQL會話。
在SQL會話頁簽,單擊創(chuàng)建SQL會話。
在創(chuàng)建SQL會話頁面,配置以下信息,其余參數(shù)無需配置,然后單擊創(chuàng)建。
參數(shù)
說明
名稱
自定義SQL會話的名稱。例如,paimon_compute。
Spark配置
請?zhí)顚懸韵耂park配置信息,以連接Paimon。
spark.sql.extensions org.apache.paimon.spark.extensions.PaimonSparkSessionExtensions spark.sql.catalog.paimon org.apache.paimon.spark.SparkCatalog spark.sql.catalog.paimon.metastore dlf spark.sql.catalog.paimon.warehouse <warehouse> spark.sql.catalog.paimon.dlf.catalog.id <dlf.catalog.id>請根據(jù)您的實際情況替換以下信息:
<warehouse>:配置數(shù)據(jù)倉庫的實際位置,請根據(jù)實際情況修改。<dlf.catalog.id>:DLF數(shù)據(jù)目錄ID,請根據(jù)實際情況修改。
單擊操作列的啟動。
步驟三:通過EMR Serverless Spark進行交互式查詢或任務調(diào)度
EMR Serverless Spark提供了交互式查詢和任務調(diào)度兩種操作模式,以滿足不同的使用需求。交互式查詢適用于快速查詢和調(diào)試,而任務調(diào)度則支持任務的開發(fā)、發(fā)布和運維,實現(xiàn)完整的生命周期管理。
在數(shù)據(jù)寫入過程中,我們可以隨時使用EMR Serverless Spark對Paimon表進行交互式查詢,以便實時獲取數(shù)據(jù)狀態(tài)和執(zhí)行快速分析。此外,通過發(fā)布開發(fā)好的任務并創(chuàng)建工作流,可以編排各項任務并完成工作流的發(fā)布。您可以配置調(diào)度策略,實現(xiàn)任務的定期調(diào)度,從而保證數(shù)據(jù)處理和分析的自動化與高效性。
交互式查詢
創(chuàng)建SQL開發(fā)。
在EMR Serverless Spark頁面,單擊左側導航欄中的數(shù)據(jù)開發(fā)。
在開發(fā)目錄頁簽下,單擊新建。
在彈出的對話框中,輸入名稱(例如,paimon_compact),類型選擇為,然后單擊確定。
在右上角選擇數(shù)據(jù)目錄、數(shù)據(jù)庫和前一步驟中啟動的SQL會話。
在新建的任務編輯器中輸入SQL語句。
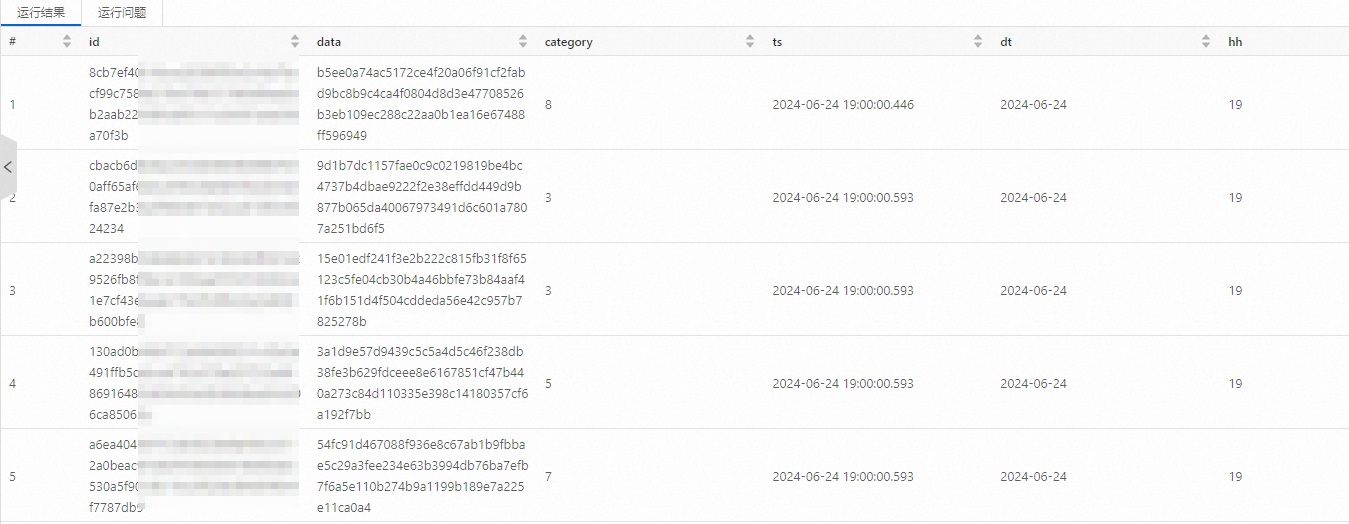
示例1:查詢
test_append_tbl表中前10行的數(shù)據(jù)。SELECT * FROM paimon.test_paimon_db.test_append_tbl limit 10;返回結果示例如下。
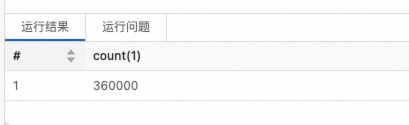
示例2:統(tǒng)計
test_append_tbl表中滿足特定條件的行數(shù)。SELECT COUNT(*) FROM paimon.test_paimon_db.test_append_tbl WHERE dt = '2024-06-24' AND hh = '19';返回結果示例如下。
運行并發(fā)布任務。
單擊運行。
返回結果信息可以在下方的運行結果中查看。如果有異常,則可以在運行問題中查看。
確認運行無誤后,單擊右上角的發(fā)布。
在發(fā)布對話框中,可以輸入發(fā)布信息,然后單擊確定。
任務調(diào)度
查詢Compact前文件信息。
在數(shù)據(jù)開發(fā)頁面,新建SQL開發(fā),查詢Paimon的files系統(tǒng)表,快速地得到Compact前文件的數(shù)據(jù)。創(chuàng)建SQL開發(fā)的具體操作,請參見SQL開發(fā)。
SELECT file_path, record_count, file_size_in_bytes FROM paimon.test_paimon_db.test_append_tbl$files WHERE partition='[2024-06-24, 19]';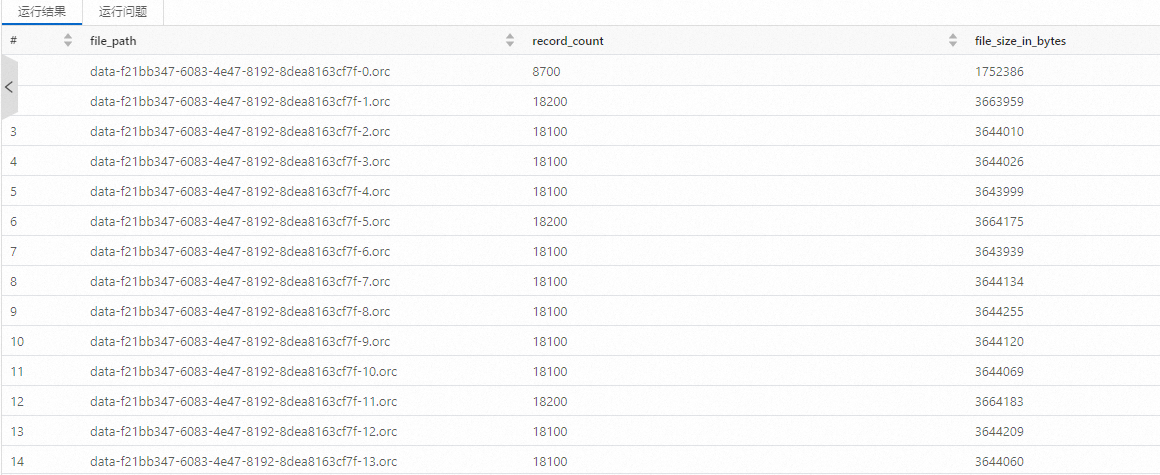
在數(shù)據(jù)開發(fā)頁面,編寫Paimon Compact SQL(例如,paimon_compact),然后完成發(fā)布。
創(chuàng)建SQL開發(fā)的具體操作,請參見SQL開發(fā)。
CALL paimon.sys.compact ( table => 'test_paimon_db.test_append_tbl', partitions => 'dt=\"2024-06-24\",hh=\"19\"', order_strategy => 'zorder', order_by => 'category' );創(chuàng)建工作流。
在EMR Serverless Spark頁面,單擊左側導航欄中的任務編排。
在任務編排頁面,單擊創(chuàng)建工作流。
在創(chuàng)建工作流面板中,輸入工作流名稱(例如,paimon_workflow_task),然后單擊下一步。
其他設置區(qū)域的參數(shù),請根據(jù)您的實際情況配置,更多參數(shù)信息請參見管理工作流。
在新建的節(jié)點畫布中,單擊添加節(jié)點。
在來源文件路徑下拉列表中選擇已發(fā)布的SQL開發(fā)(paimon_compact),填寫Spark配置參數(shù),然后單擊保存。
參數(shù)
說明
名稱
自定義SQL會話的名稱。例如,paimon_compute。
Spark配置
請?zhí)顚懸韵耂park配置信息,以連接Paimon。
spark.sql.extensions org.apache.paimon.spark.extensions.PaimonSparkSessionExtensions spark.sql.catalog.paimon org.apache.paimon.spark.SparkCatalog spark.sql.catalog.paimon.metastore dlf spark.sql.catalog.paimon.warehouse <warehouse> spark.sql.catalog.paimon.dlf.catalog.id <dlf.catalog.id>請根據(jù)您的實際情況替換以下信息:
<warehouse>:配置數(shù)據(jù)倉庫的實際位置,請根據(jù)實際情況修改。<dlf.catalog.id>:DLF數(shù)據(jù)目錄ID,請根據(jù)實際情況修改。
在新建的節(jié)點畫布中,單擊發(fā)布工作流,然后單擊確定。
運行工作流。
在任務編排頁面,單擊新建工作流(例如,paimon_workflow_task)的工作流名稱。
在工作流實例列表頁面,單擊手動運行。
在觸發(fā)運行對話框中,單擊確定。
驗證Compact效果。
工作流調(diào)度執(zhí)行成功后,再次執(zhí)行與開始相同的SQL查詢,對比Compact前后文件的數(shù)量、記錄數(shù)和大小,以驗證Compact操作的效果。
SELECT file_path, record_count, file_size_in_bytes FROM paimon.test_paimon_db.test_append_tbl$files WHERE partition='[2024-06-24, 19]';