在PySpark程序中使用Python第三方庫
PySpark作業(yè)往往需要借助Python第三方庫來增強數(shù)據(jù)處理和分析能力。本文檔詳細介紹了如何利用Conda和PEX這兩種方法,有效地將這些庫集成到Serverless Spark環(huán)境中,確保作業(yè)在分布式計算場景下的穩(wěn)定性和靈活性。
背景信息
Conda是一個跨平臺的包管理和環(huán)境管理系統(tǒng),它允許用戶輕松創(chuàng)建、保存、加載和切換多個環(huán)境,每個環(huán)境都可以擁有獨立的Python版本和庫依賴。PEX (Python EXecutable) 是一個工具,它可以將Python應用及其所有依賴打包進一個可執(zhí)行文件中。
前提條件
已創(chuàng)建一臺使用Alibaba Cloud Linux 3系統(tǒng),且開啟公網(wǎng)的ECS實例,詳情請參見自定義購買實例。
說明如果您在EMR on ECS頁面已有的EMR集群中有空閑節(jié)點,也可以直接利用這些空閑節(jié)點。
已創(chuàng)建工作空間,詳情請參見創(chuàng)建工作空間。
使用限制
已安裝Python 3.8及以上版本。本文以Python 3.8為例介紹。
使用Conda
步驟一:Conda環(huán)境構建與部署
通過以下命令安裝Miniconda。
wget https://repo.continuum.io/miniconda/Miniconda3-latest-Linux-x86_64.sh chmod +x Miniconda3-latest-Linux-x86_64.sh ./Miniconda3-latest-Linux-x86_64.sh -b source miniconda3/bin/activate構建使用Python 3.8和numpy的Conda環(huán)境。
conda create -y -n pyspark_conda_env -c conda-forge conda-pack numpy python=3.8 conda activate pyspark_conda_env conda pack -f -o pyspark_conda_env.tar.gz
步驟二:上傳資源文件至OSS
單擊kmeans.py和kmeans_data.txt,下載所需資源文件。
您也可以創(chuàng)建示例腳本
kmeans.py和數(shù)據(jù)文件kmeans_data.txt,內(nèi)容如下所示。""" A K-means clustering program using MLlib. This example requires NumPy (http://www.numpy.org/). """ import sys import numpy as np from pyspark import SparkContext from pyspark.mllib.clustering import KMeans def parseVector(line): return np.array([float(x) for x in line.split(' ')]) if __name__ == "__main__": if len(sys.argv) != 3: print("Usage: kmeans <file> <k>", file=sys.stderr) sys.exit(-1) sc = SparkContext(appName="KMeans") lines = sc.textFile(sys.argv[1]) data = lines.map(parseVector) k = int(sys.argv[2]) model = KMeans.train(data, k) print("Final centers: " + str(model.clusterCenters)) print("Total Cost: " + str(model.computeCost(data))) sc.stop()0.0 0.0 0.0 0.1 0.1 0.1 0.2 0.2 0.2 9.0 9.0 9.0 9.1 9.1 9.1 9.2 9.2 9.2上傳
pyspark_conda_env.tar.gz、kmeans.py和kmeans_data.txt至OSS,上傳操作可以參見簡單上傳。
步驟三:開發(fā)并運行任務
在EMR Serverless Spark頁面,單擊左側(cè)的數(shù)據(jù)開發(fā)。
單擊新建。
輸入名稱,類型選擇,單擊確定。
在右上角選擇隊列。
在新建的開發(fā)頁簽中,配置以下信息,其余參數(shù)無需配置,然后單擊運行。
參數(shù)
說明
主Python資源
選擇OSS資源,填寫您上傳
kmeans.py至OSS的路徑。例如,oss://<yourBucketName>/kmeans.py。運行參數(shù)
填寫數(shù)據(jù)文件
kmeans_data.txt上傳到OSS的路徑。填寫格式為
oss://<yourBucketName>/kmeans_data.txt 2。archives資源
選擇OSS資源,填寫您上傳
pyspark_conda_env.tar.gz至OSS的路徑。填寫格式為:
oss://<yourBucketName>/pyspark_conda_env.tar.gz#condaenv。Spark配置
spark.pyspark.driver.python ./condaenv/bin/python spark.pyspark.python ./condaenv/bin/python運行任務后,在下方的運行記錄區(qū)域,單擊任務操作列的詳情。
在任務歷史中的開發(fā)任務頁面,您可以查看相關的日志信息。
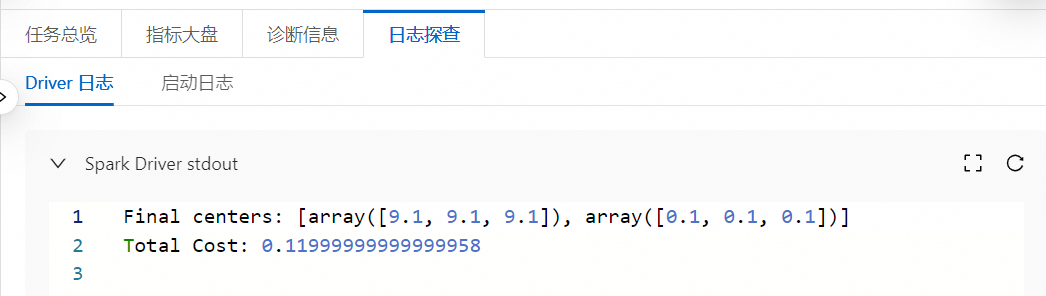
使用PEX
步驟一:PEX文件打包與執(zhí)行
安裝PEX與wheel工具。
pip3.8 install --user pex wheel \ --trusted-host mirrors.cloud.aliyuncs.com \ -i http://mirrors.cloud.aliyuncs.com/pypi/simple/下載所需庫的wheel文件至臨時目錄。
pip3.8 wheel -w /tmp/wheel \ pyspark==3.3.1 pandas==1.5.3 pyarrow==15.0.1 numpy==1.24.4 \ --trusted-host mirrors.cloud.aliyuncs.com \ -i http://mirrors.cloud.aliyuncs.com/pypi/simple/生成PEX文件。
pex -f /tmp/wheel --no-index \ pyspark==3.3.1 pandas==1.5.3 pyarrow==15.0.1 numpy==1.24.4 \ -o spark331_pandas153.pex
步驟二:上傳PEX文件至OSS
單擊kmeans.py和kmeans_data.txt,下載所需資源文件。
上傳
spark331_pandas153.pex、kmeans.py和kmeans_data.txt至OSS,上傳操作可以參見簡單上傳。說明本文示例使用的Spark版本是3.3.1,同時包含pandas、pyarrow以及numpy等第三方Python庫。您也可以根據(jù)選擇的引擎版本打包其他版本的PySpark環(huán)境。有關引擎版本的詳細信息,請參見引擎版本介紹。
步驟三:開發(fā)并運行任務
在EMR Serverless Spark頁面,單擊左側(cè)的數(shù)據(jù)開發(fā)。
單擊新建。
輸入名稱,類型選擇,單擊確定。
在右上角選擇隊列。
在新建的開發(fā)頁簽中,配置以下信息,其余參數(shù)無需配置,然后單擊運行。
參數(shù)
說明
主Python資源
選擇OSS資源,填寫您上傳
kmeans.py至OSS的路徑。例如,oss://<yourBucketName>/kmeans.py。運行參數(shù)
填寫數(shù)據(jù)文件
kmeans_data.txt上傳到OSS的路徑。填寫格式為
oss://<yourBucketName>/kmeans_data.txt 2。files資源
選擇OSS資源,填寫您上傳
spark331_pandas153.pex至OSS的路徑。例如,oss://<yourBucketName>/spark331_pandas153.pex。Spark配置
spark.pyspark.driver.python ./spark331_pandas153.pex spark.pyspark.python ./spark331_pandas153.pex運行任務后,在下方的運行記錄區(qū)域,單擊任務操作列的詳情。
在任務歷史中的開發(fā)任務頁面,您可以查看相關的日志信息。
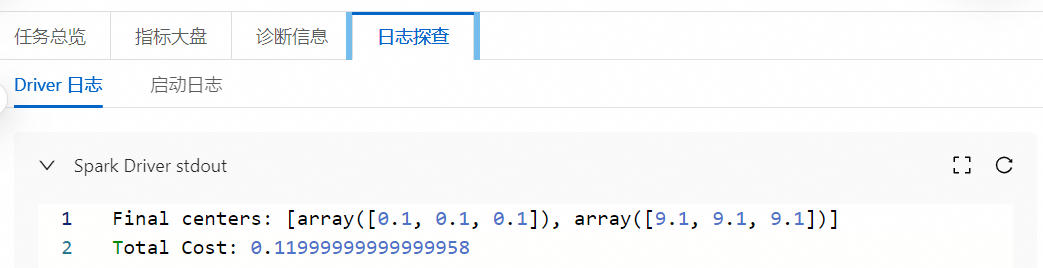
相關文檔
本文以PySpark開發(fā)為例,如果您想通過其他方式進行開發(fā),可以參見Application開發(fā)。