在Notebook中執行交互式PySpark任務時往往需要借助Python第三方庫來增強數據處理和分析能力。本文將以三種方式為您介紹如何在Notebook中安裝Python第三方庫。
背景信息
在交互式PySpark開發過程中,可以使用Python第三方庫以提升數據處理與分析的靈活性及易用性。以下三種方式均能幫助您實現這一目標,建議根據實際情況選擇最適合的方式。
方式 | 適用場景 |
在Notebook中處理與Spark無關的變量,例如處理通過Spark計算得到的返回值或是自定義的變量等。 重要 重啟Notebook會話后需要重新安裝這些庫。 | |
需要在PySpark中使用Python第三方庫處理數據,且希望Notebook會話在每次啟動時都能默認預裝這些第三方庫。 | |
需要在PySpark中使用Python第三方庫處理數據的場景,例如使用Python第三方庫進行Spark分布式計算。 |
前提條件
已創建工作空間,詳情請參見創建工作空間。
已創建Notebook會話,詳情請參見管理Notebook會話。
已創建Notebook開發,詳情請參見Notebook開發。
操作流程
方式一:使用pip安裝Python庫
進入Notebook開發頁面。
在左側導航欄,選擇。
在Spark頁面,單擊目標工作空間名稱。
在EMR Serverless Spark頁面,單擊左側導航欄中的數據開發。
雙擊已創建的Notebook開發。
在一個Notebook的Python單元格中,輸入以下命令安裝scikit-learn庫,然后單擊
 圖標。
圖標。pip install scikit-learn在一個Notebook的Python單元格中,輸入以下命令,然后單擊
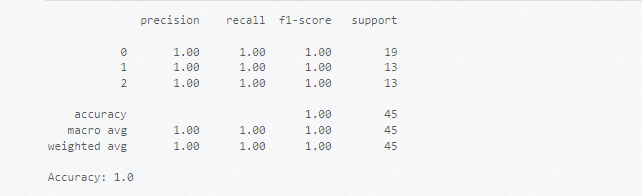
圖標。# 導入庫并準備相關數據集。 from sklearn import datasets # 加載內置的數據集,例如Iris數據集。 iris = datasets.load_iris() X = iris.data # 特征數據 y = iris.target # 標簽 # 劃分數據集。 from sklearn.model_selection import train_test_split # 劃分訓練集和測試集。 X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42) # 使用向量機模型進行訓練。 from sklearn.svm import SVC # 創建分類器實例。 clf = SVC(kernel='linear') # 使用線性核。 # 訓練模型。 clf.fit(X_train, y_train) # 使用訓練好的模型進行預測。 y_pred = clf.predict(X_test) # 評估模型性能。 from sklearn.metrics import classification_report, accuracy_score print(classification_report(y_test, y_pred)) print("Accuracy:", accuracy_score(y_test, y_pred))執行結果如下所示。
方式二:通過運行環境管理配置自定義Python環境
步驟一:創建運行環境
進入運行環境管理頁面。
在左側導航欄,選擇。
在Spark頁面,單擊目標工作空間名稱。
在EMR Serverless Spark頁面,選擇左側導航欄中的運行環境管理。
單擊創建運行環境。
在創建運行環境頁面,單擊添加庫。
更多參數信息,請參見管理運行環境。
在新建庫中,使用PyPI來源類型,配置PyPI Package參數,然后單擊確定。
在PyPI Package中填寫庫的名稱及版本,不指定版本時,默認安裝最新版本。例如,
scikit-learn。單擊創建。
創建后將開始初始化環境。
步驟二:使用運行環境
在編輯會話之前,您需要先停止會話。
進入Notebook會話頁簽。
在EMR Serverless Spark頁面,選擇左側導航欄中的。
單擊Notebook會話頁簽。
單擊目標Notebook會話操作列的編輯。
在運行環境下拉列表中選擇前一步驟創建的運行環境,單擊保存更改。
單擊右上角的啟動。
步驟三:利用Scikit-learn庫進行數據分類
進入Notebook開發頁面。
在EMR Serverless Spark頁面,單擊左側導航欄中的數據開發。
雙擊已創建的Notebook開發。
在一個Notebook的Python單元格中,輸入以下命令,然后單擊
圖標。# 導入庫并準備相關數據集。 from sklearn import datasets # 加載內置的數據集,例如Iris數據集。 iris = datasets.load_iris() X = iris.data # 特征數據 y = iris.target # 標簽 # 劃分數據集。 from sklearn.model_selection import train_test_split # 劃分訓練集和測試集。 X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42) # 使用向量機模型進行訓練。 from sklearn.svm import SVC # 創建分類器實例。 clf = SVC(kernel='linear') # 使用線性核。 # 訓練模型。 clf.fit(X_train, y_train) # 使用訓練好的模型進行預測。 y_pred = clf.predict(X_test) # 評估模型性能。 from sklearn.metrics import classification_report, accuracy_score print(classification_report(y_test, y_pred)) print("Accuracy:", accuracy_score(y_test, y_pred))執行結果如下所示。
方式三:通過Spark參數配置自定義Python環境
使用該方式時,需要確保ipykernel和jupyter_client版本需符合要求,Python版本不低于3.8,且在Linux環境下打包。
步驟一:Conda環境構建與部署
通過以下命令安裝Miniconda。
wget https://repo.continuum.io/miniconda/Miniconda3-latest-Linux-x86_64.sh chmod +x Miniconda3-latest-Linux-x86_64.sh ./Miniconda3-latest-Linux-x86_64.sh -b source miniconda3/bin/activate構建使用Python 3.8和numpy的Conda環境。
# 創建并激活conda環境 conda create -y -n pyspark_conda_env python=3.8 conda activate pyspark_conda_env # 安裝第三方庫 pip install numpy \ ipykernel~=6.29 \ jupyter_client~=8.6 \ jieba \ conda-pack # 打包環境 conda pack -f -o pyspark_conda_env.tar.gz
步驟二:上傳資源文件至OSS
上傳打包好的pyspark_conda_env.tar.gz至阿里云OSS,并記錄下完整的OSS路徑,上傳操作可以參見簡單上傳。
步驟三:配置并啟動Notebook會話
在編輯會話之前,您需要先停止會話。
進入Notebook會話頁簽。
在EMR Serverless Spark頁面,選擇左側導航欄中的。
單擊Notebook會話頁簽。
單擊目標Notebook會話操作列的編輯。
在Spark配置中,添加以下配置信息,單擊保存更改。
spark.archives oss://<yourBucket>/path/to/pyspark_conda_env.tar.gz#env spark.pyspark.python ./env/bin/python說明配置中的
<yourBucket>/path/to,請替換為您實際的OSS上傳路徑。單擊右上角的啟動。
步驟四:利用Jieba分詞處理文本數據
Jieba是一個中文文本分詞Python第三方庫,其開源許可證請參見LICENSE。
進入Notebook開發頁面。
在EMR Serverless Spark頁面,單擊左側導航欄中的數據開發。
雙擊已創建的Notebook開發。
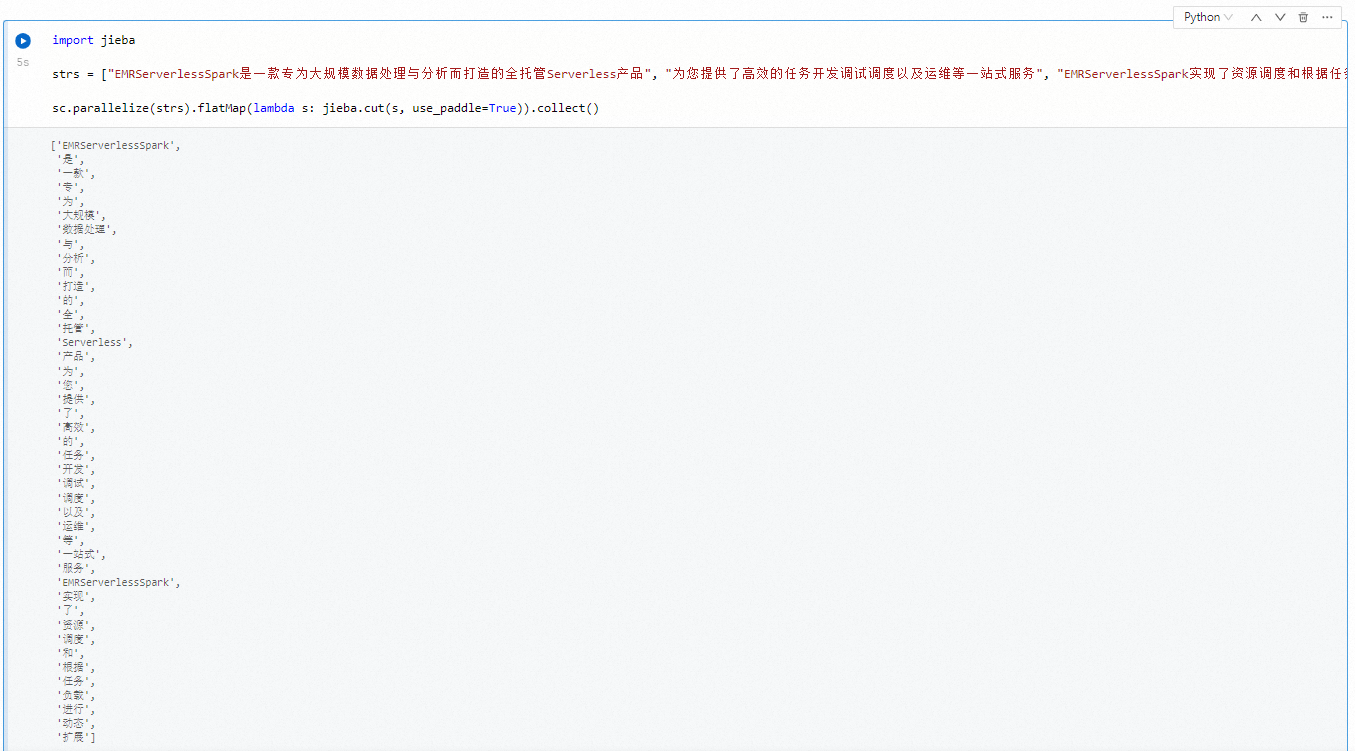
在新的一個Python單元格中,輸入以下命令以使用Jieba進行中文分詞,然后單擊
圖標。import jieba strs = ["EMRServerlessSpark是一款專為大規模數據處理與分析而打造的全托管Serverless產品", "為您提供了高效的任務開發調試調度以及運維等一站式服務", "EMRServerlessSpark實現了資源調度和根據任務負載進行動態擴展"] sc.parallelize(strs).flatMap(lambda s: jieba.cut(s, use_paddle=True)).collect()執行結果如下所示。