本文將介紹企業在沒有向量數據的情況下,如何通過OpenSearch向量檢索版,快速搭建圖像搜索服務。
用戶可以直接導入圖片源數據,在OpenSearch內部便捷完成圖片向量化、向量搜索等步驟,實現以圖搜圖、以文搜圖等多種圖像檢索能力。
方案架構
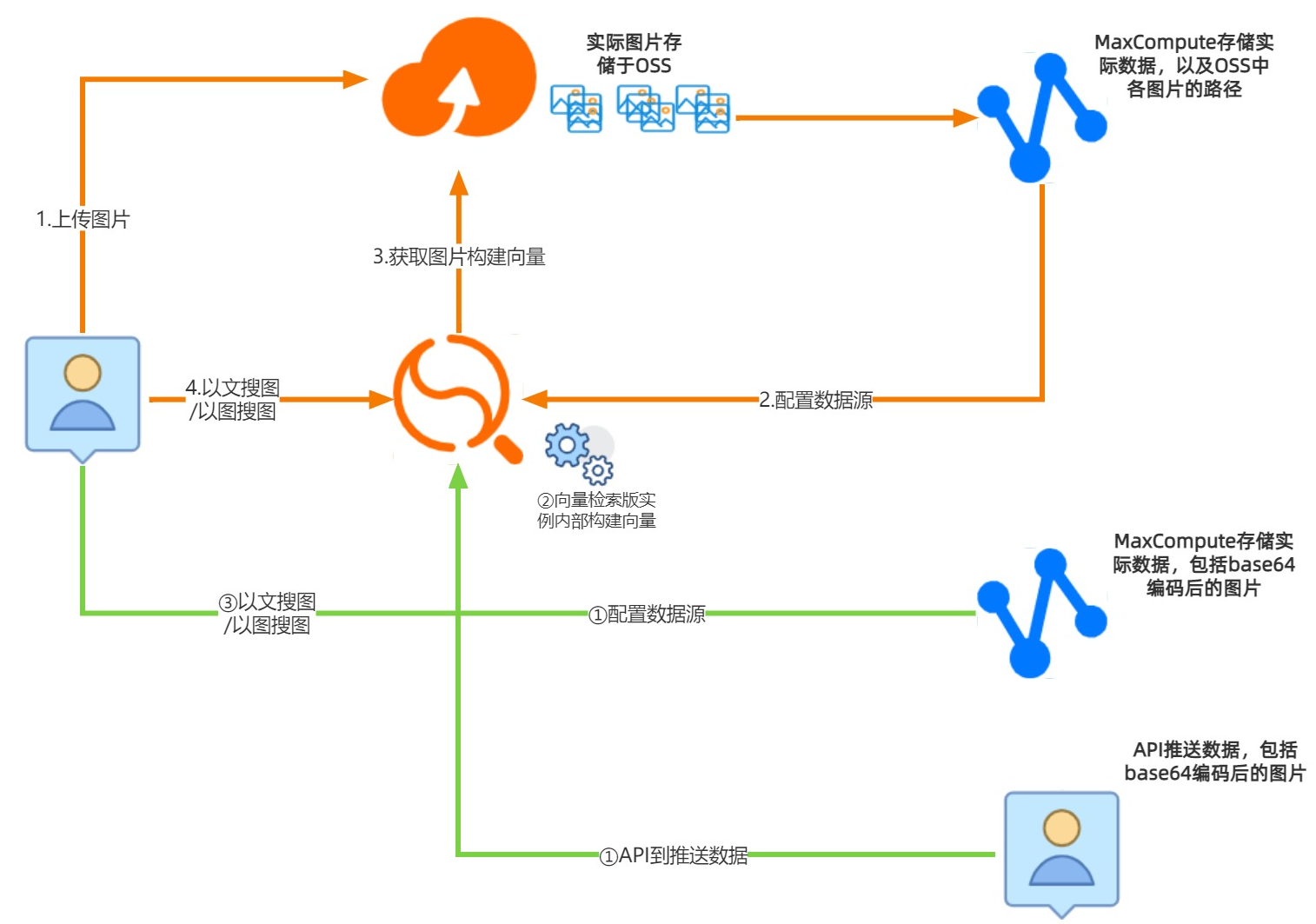
用戶可以通過3種不同的方式上傳圖片進行圖搜引擎的搭建:
OSS+MaxCompute+OpenSearch向量檢索版:用戶先將圖片上傳至OSS中,在MaxCompute中存儲業務表數據以及每條數據對應的圖片地址(OSS里的路徑,比如/image/1.jpg)
MaxCompute+OpenSearch向量檢索版:用戶將圖片通過base64編碼后的圖片及其表數據存儲在MaxCompute中
API+OpenSearch向量檢索版:用戶通過OpenSearch向量檢索版給出的數據推送接口,將base64編碼后的圖片及其表數據推送到OpenSearch向量檢索版實例中
本文演示的是OSS+MaxCompute+OpenSearch向量檢索版搭建圖搜引擎。
環境準備
1、創建AK和SK
第一次開通阿里云賬號并登錄控制臺時,會提示先創建access key才能繼續使用。
創建及使用應用依賴access key參數,主賬號下access key參數不能為空。
在為主賬號創建access key參數后,還可以再創建RAM子賬號access key通過RAM子賬號進行訪問,RAM子賬號賦予對應訪問權限,請參考RAM(子賬號)的創建及授權。
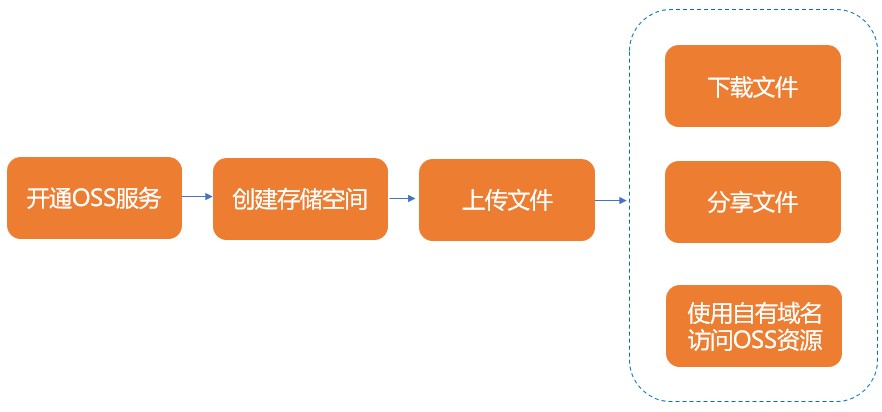
2、創建對象存儲OSS
本文在OSS中上傳了1000張圖片:
部分圖片類型如下:
購買OpenSearch向量檢索版實例
進入OpenSearch控制臺,在左上角切換到OpenSearch-向量檢索版:

進入向量檢索版控制臺后,在實例管理界面,點擊創建實例:

商品版本選擇向量檢索版,選擇地區,配置“查詢節點個數”、“查詢節點規格”、“數據節點數量”、“數據節點規格”、“單數據節點總存儲空間”,設置“專有網絡”和“虛擬交換機”,最后按提示要求設置用戶名和用戶密碼(用于查詢時校驗權限,非阿里云賬號密碼),點擊“立即購買”:
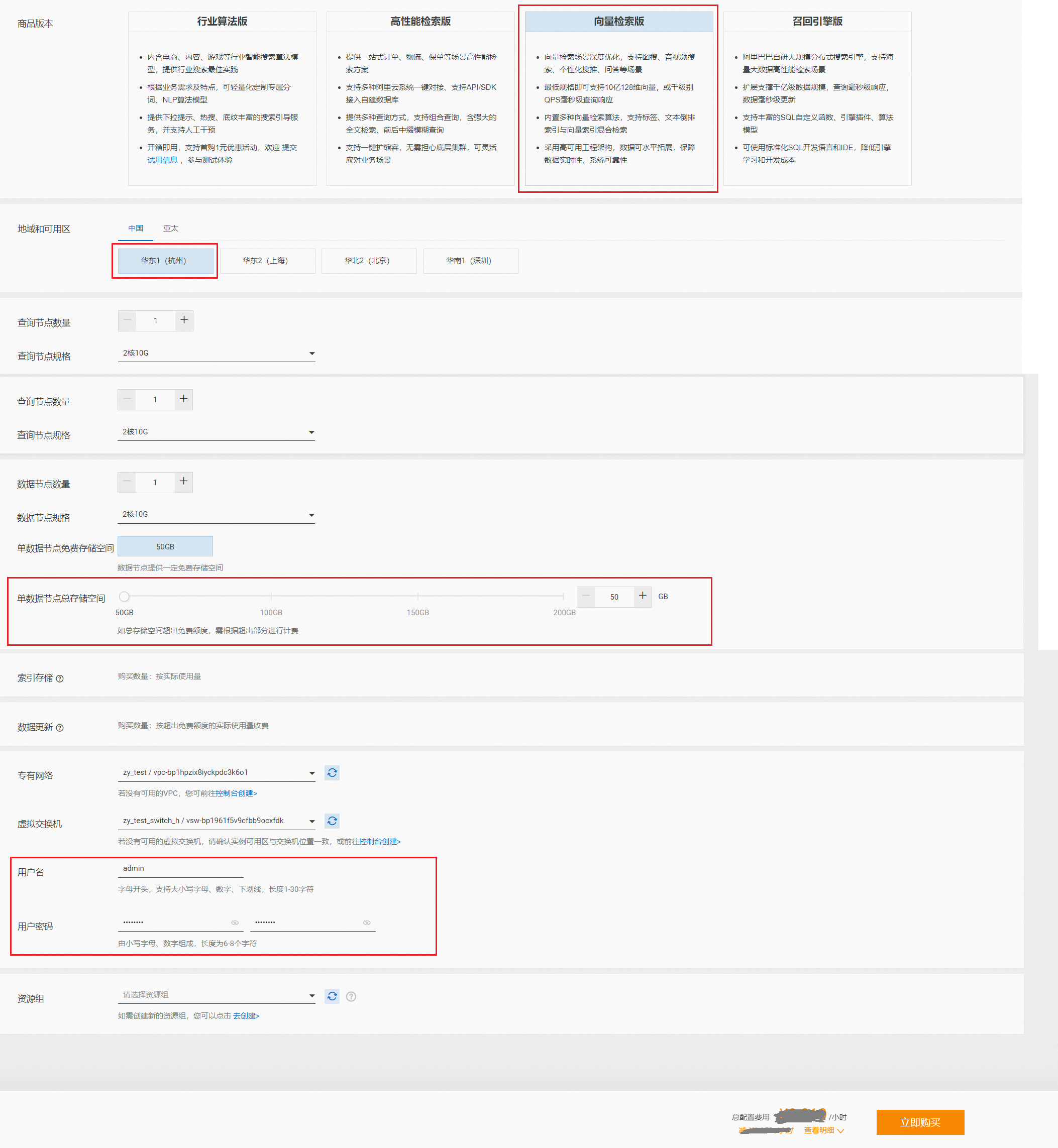
購買的查詢節點和數據節點的個數及規格,需根據自身業務進行規劃,確定規格后實際費用可在售賣頁自動生成。
專有網絡和虛擬交換的配置一定要和訪問向量檢索版實例的ECS機器保持一致。否則在訪問向量檢索版實例時會報錯{'errors':{'code':'403','message':'Forbidden'}}
單數據節點存儲空間有免費額度,用戶也可申請額外額度,按額外額度部分收費(步長50GB)
在確認訂單界面,查看服務協議,確認無誤后,點擊立即開通:
購買成功后,點擊管理控制臺,即可在實例管理界面查看已購買的向量檢索版實例:
新購的實例會設置一個默認實例名稱,可在操作欄下點擊管理按鈕,進入詳情頁進行修改:

點擊修改圖標,按提示框要求修改實例名稱最后點擊確認:

配置集群
新購買的實例,在其詳情頁中,實例狀態為“待配置”,并且會自動部署一個與購買的查詢節點和數據節點的個數及規格一致的空集群,之后需要為該集群配置數據源--->配置索引--->索引重建,之后才可正常搜索。

1、配置數據源
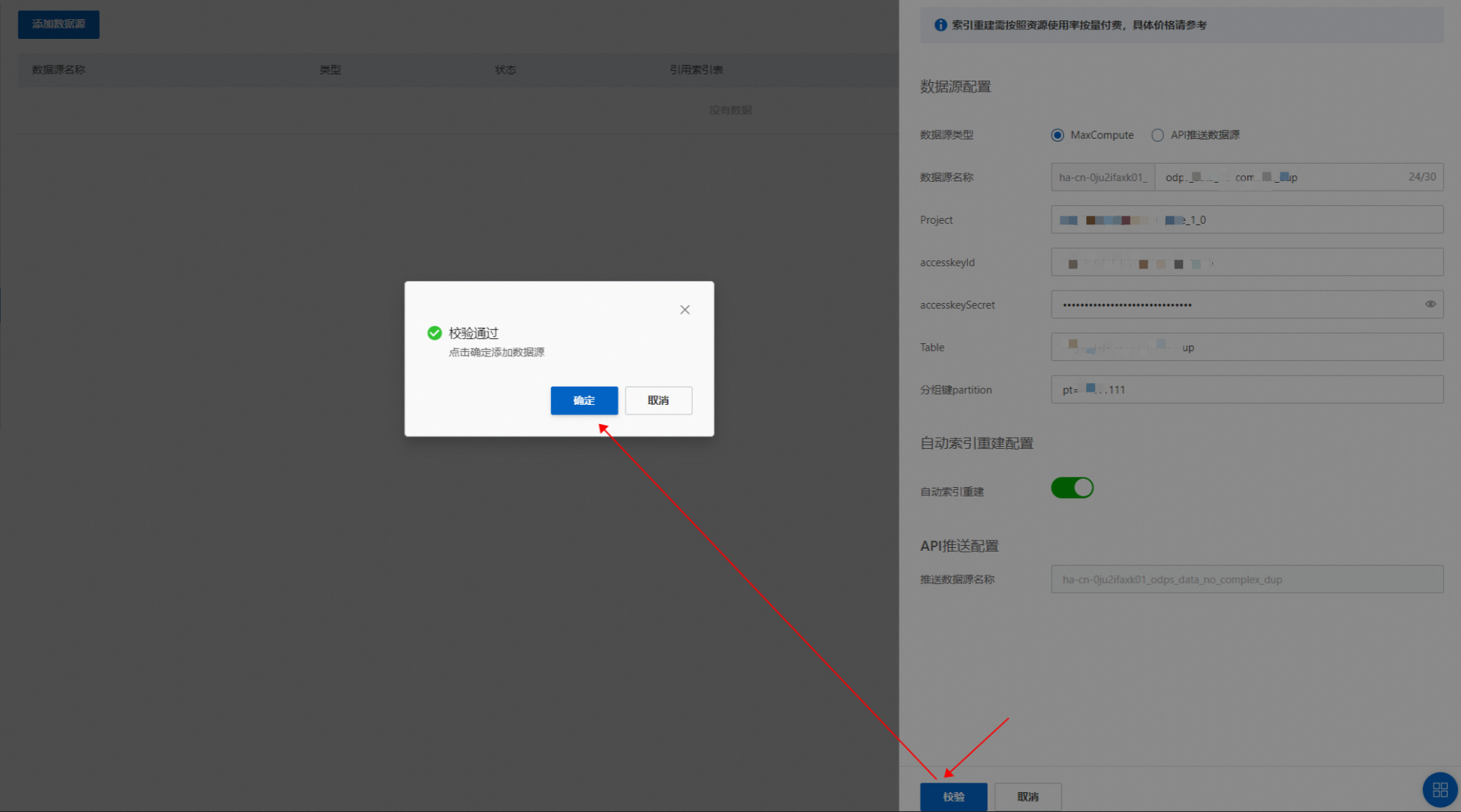
配置數據源(目前支持的數據源有“MaxCompute數據源”和“API推送數據源”)這里以MaxCompute數據源為例:點擊“添加數據源”,數據源類型選擇“MaxCompute”,設置project、accesskeyID、accesskeyId、accesskeySecret、Table、分組鍵partition,可按需選擇是否開啟“自動索引重建”:
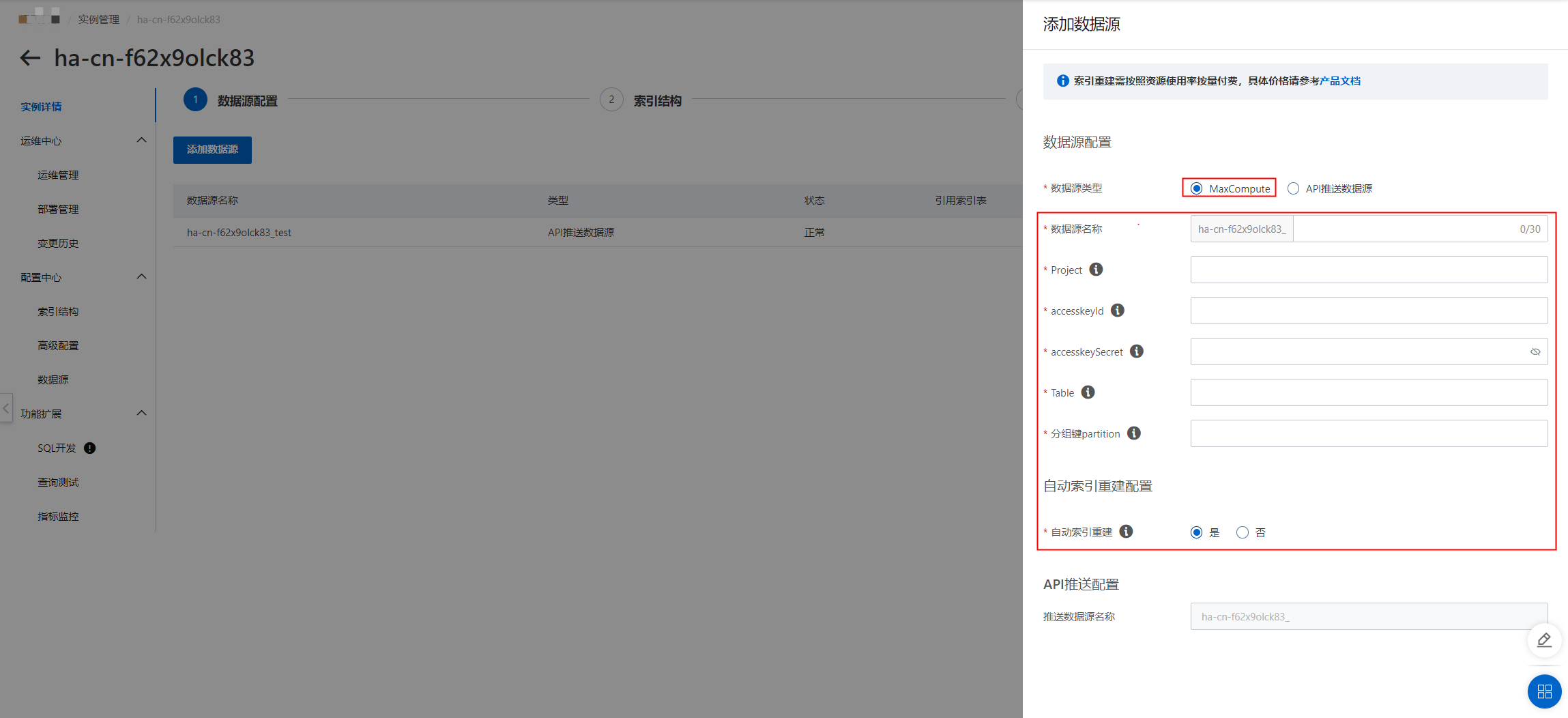
校驗成功之后,點擊“確定”,完成數據源的添加:
2、配置索引結構
數據源配置成功后,需點擊下一步配置索引結構:

添加索引表:

配置索引表,模板選擇“向量:圖片搜索”模板,數據情況選擇“需要將原始數據轉為向量”:

配置字段:此處介紹圖片存儲于OSS和基于base64編碼圖片方案配置:
圖片存儲于OSS
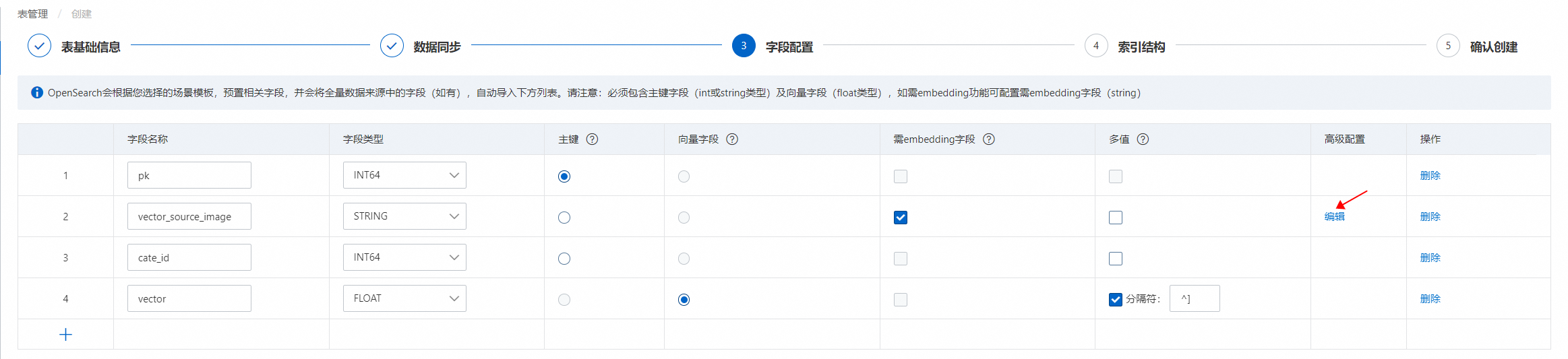
模板選擇“向量:圖片搜索”模板后,系統默認生成4個預置字段id(主鍵)、cate_id(類目字段)、vector(向量字段)、vector_source_image(存儲圖片路徑的字段),用戶選擇MaxCompute數據源后,從數據源同步的字段,展示在預置字段下方。
4.1. 配置“vector_source_image”字段:(字段類型需要為STRING)
用戶可根據業務表字段對預置字段名稱進行修改,但需要保證該字段的高級配置無誤:
具體配置如下:
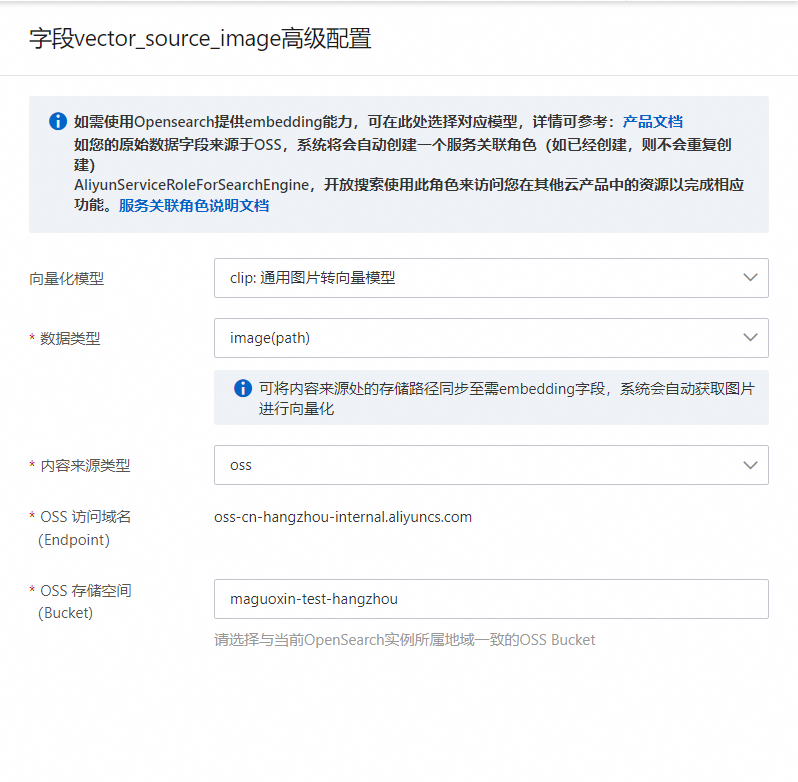
數據類型:選擇image(path)
內容來源類型:選擇oss
OSS存儲空間:填寫當前賬號可以訪問的且存儲需要向量化圖片的OSS存儲空間
假設某張圖片在OSS的路徑為“/測試圖片/image/10031.png”,那么該字段的內容也必須是“/測試圖片/image/10031.png”,以下圖舉例:
OSS的路徑:

MaxCompute字段值:

4.2. 配置vector字段:(字段類型需要為FLOAT)
配置完“vector_source_image”字段后,引擎可以通過OSS訪問到對應的圖片,如果需要“將原始數據轉為向量數據”,還需要配置vector字段,用戶可根據業務表字段對預置字段名稱進行修改,但需要保證該字段的高級配置無誤:

具體配置如下:
{
"vector_model": "clip",
"vector_modal": "image",
"vector_source_field": "vector_source_image"
}vector_model:向量化模型,目前支持通用圖片和電商增強圖片轉化
選擇通用類型,
"vector_model": "clip",通用圖片轉向量模型。選擇電商增強:
"vector_model": "clip_ecom",電商增強圖片轉向量模型。
vector_modal:填寫
imagevector_source_field:配置存儲OSS圖片路徑的字段,默認為vector_source_image
4.3. schema示例:
"fields": [
{
"field_name": "id",
"field_type": "INT64",
"compress_type": "equal"
},
{
"user_defined_param": {
"content_type": "oss",
"oss_endpoint": "",
"oss_bucket": "OSS的Bucket名稱",
"oss_secret": "可以訪問OSS的賬號SK",
"oss_access_key": "可以訪問OSS的賬號AK"
},
"field_name": "vector_source_image",
"field_type": "STRING",
"compress_type": "uniq"
},
{
"field_name": "cate_id",
"field_type": "INT64",
"compress_type": "equal"
},
{
"user_defined_param": {
"vector_model": "clip",
"vector_modal": "image",
"vector_source_field": "vector_source_image"
},
"field_name": "vector",
"field_type": "FLOAT",
"multi_value": true
}
]base64編碼的圖片
模板選擇“向量:圖片搜索”模板后,系統默認生成4個預置字段id(主鍵)、cate_id(類目字段)、vector(向量字段)、vector_source_image(存儲圖片base64編碼后的字段),用戶選擇MaxCompute數據源后,從數據源同步的字段,展示在預置字段下方。
4.1. 配置“vector_source_image”字段:(字段類型需要為STRING)
用戶可根據業務表字段對預置字段名稱進行修改:

注意:需要手動將“vector_source_image”字段中的高級配置刪除,保留{}即可。
4.2. 配置vector字段:
配置完“vector_source_image”字段后,引擎可以通過OSS訪問到對應的圖片,如果需要“將原始數據轉為向量數據”,還需要配置vector字段,用戶可根據業務表字段對預置字段名稱進行修改,但需要保證該字段的高級配置無誤:

具體配置如下:
{
"vector_model": "clip",
"vector_modal": "image",
"vector_source_field": "vector_source_image"
}vector_model:填寫
clipvector_modal:填寫
imagevector_source_field:配置存儲OSS圖片路徑的字段,默認為vector_source_image
4.3. schema示例:
"fields": [
{
"field_name": "id",
"field_type": "INT64",
"compress_type": "equal"
},
{
"field_name": "vector_source_image",
"field_type": "STRING",
"compress_type": "uniq"
},
{
"field_name": "cate_id",
"field_type": "INT64",
"compress_type": "equal"
},
{
"user_defined_param": {
"vector_model": "clip",
"vector_modal": "image",
"vector_source_field": "vector_source_image"
},
"field_name": "vector",
"field_type": "FLOAT",
"multi_value": true
}
]模板選擇“向量:圖片搜索”模板后,默認生成兩個索引,分別為主鍵索引(id)和向量索引(vector),字段“vector_source_image”和“vector”高級配置完成后,在索引設置中“vector”索引會自動生成高級配置:(類型需要為CUSTOMIZED)
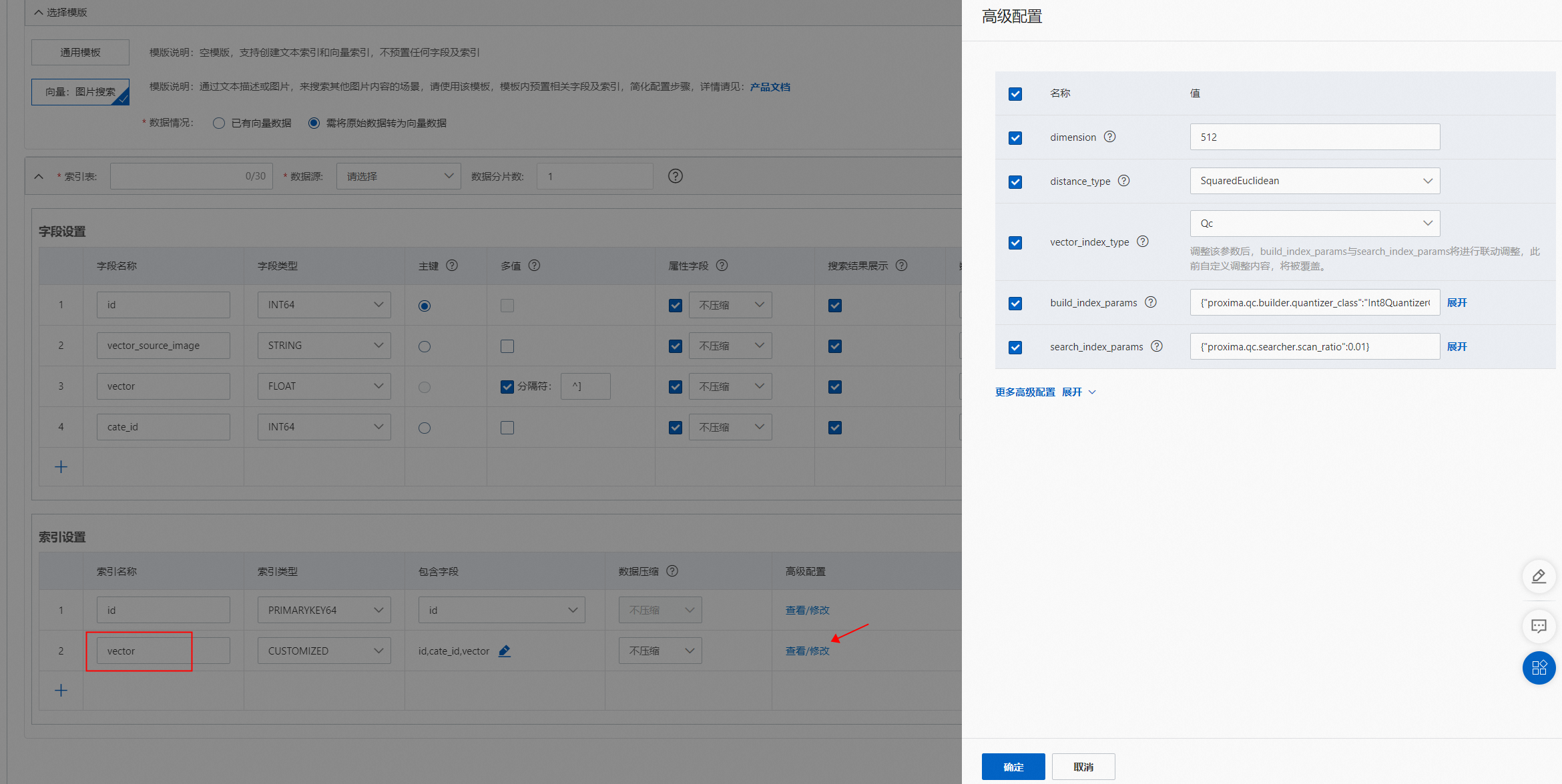
用戶需根據字段的配置修改vector索引包含的字段:
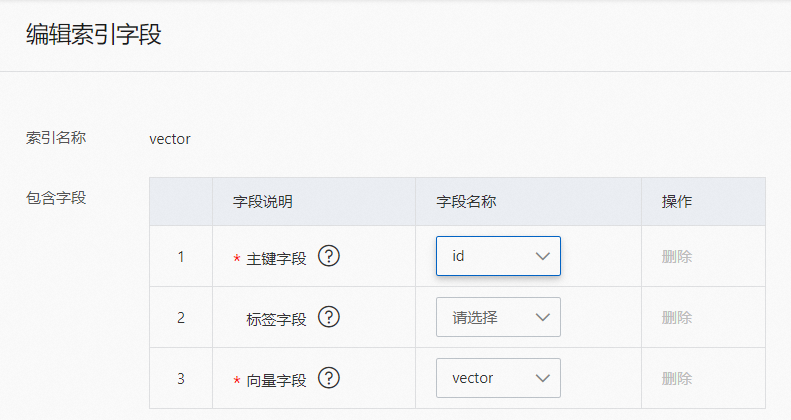
通過引擎將圖片生成的向量,默認為512維,并且不支持修改。
schema示例:
"indexs": [
{
"index_name": "id",
"index_type": "PRIMARYKEY64",
"index_fields": "id",
"has_primary_key_attribute": true,
"is_primary_key_sorted": false
},
{
"index_name": "vector",
"index_type": "CUSTOMIZED",
"index_fields": [
{
"field_name": "id",
"boost": 1
},
{
"field_name": "vector",
"boost": 1
}
],
"parameters": {
"dimension": "512",
"distance_type": "SquaredEuclidean",
"vector_index_type": "Qc",
"build_index_params": "{\"proxima.qc.builder.quantizer_class\":\"Int8QuantizerConverter\",\"proxima.qc.builder.quantize_by_centroid\":true,\"proxima.qc.builder.optimizer_class\":\"BruteForceBuilder\",\"proxima.qc.builder.thread_count\":10,\"proxima.qc.builder.optimizer_params\":{\"proxima.linear.builder.column_major_order\":true},\"proxima.qc.builder.store_original_features\":false,\"proxima.qc.builder.train_sample_count\":3000000,\"proxima.qc.builder.train_sample_ratio\":0.5}",
"search_index_params": "{\"proxima.qc.searcher.scan_ratio\":0.01}",
"embedding_delimiter": ",",
"major_order": "col",
"linear_build_threshold": "5000",
"min_scan_doc_cnt": "20000",
"enable_recall_report": "false",
"is_embedding_saved": "false",
"enable_rt_build": "false",
"builder_name": "QcBuilder",
"searcher_name": "QcSearcher"
},
"indexer": "aitheta2_indexer"
}
]3、索引重建
配置完成后,點擊保存版本,并在彈框后填寫備注(可選),點擊發布:
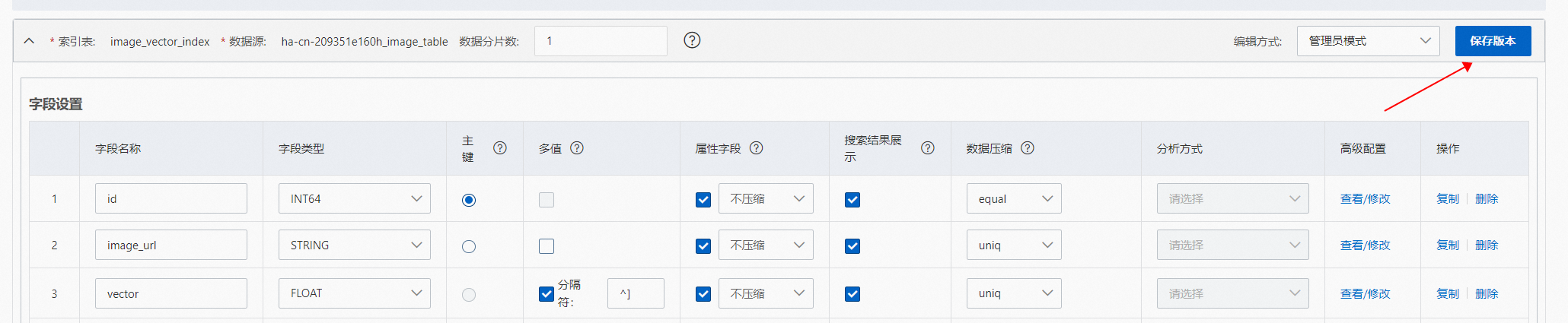
等待索引發布完成后,可點擊“下一步”進行索引重建:

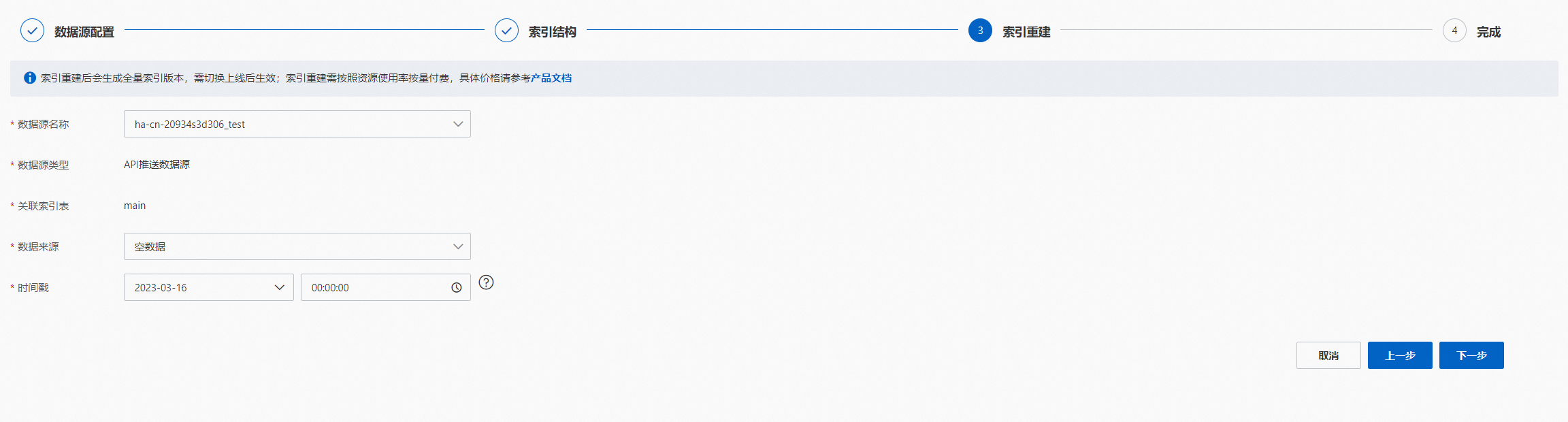
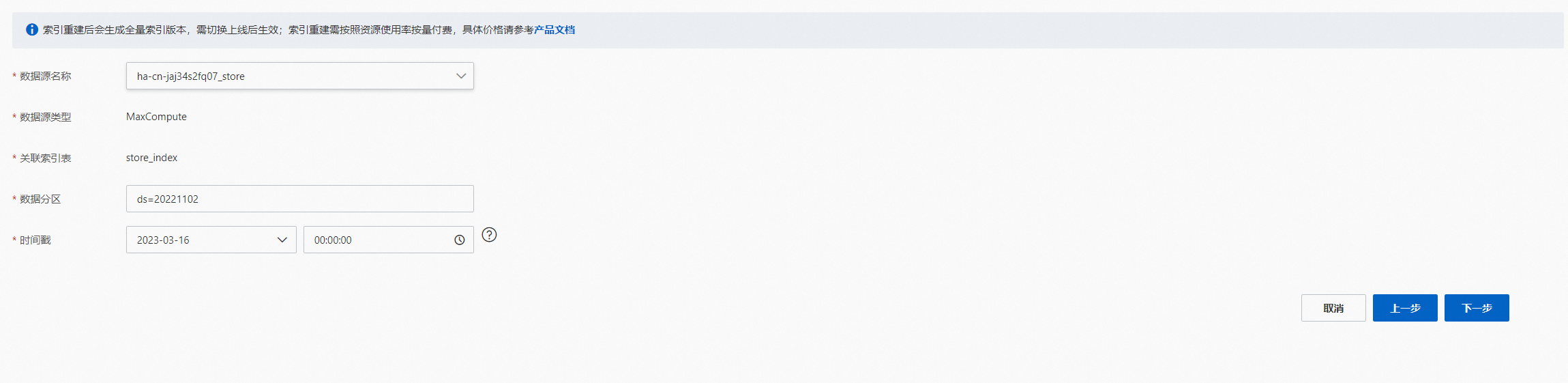
索引重建,選擇索引重建需要配置的參數項,點擊“下一步”:
API推送數據源:
MaxCompute數據源:
可在運維中心>歷史變更>數據源變更查看索引重建進度,進度完成后即可進行查詢測試:
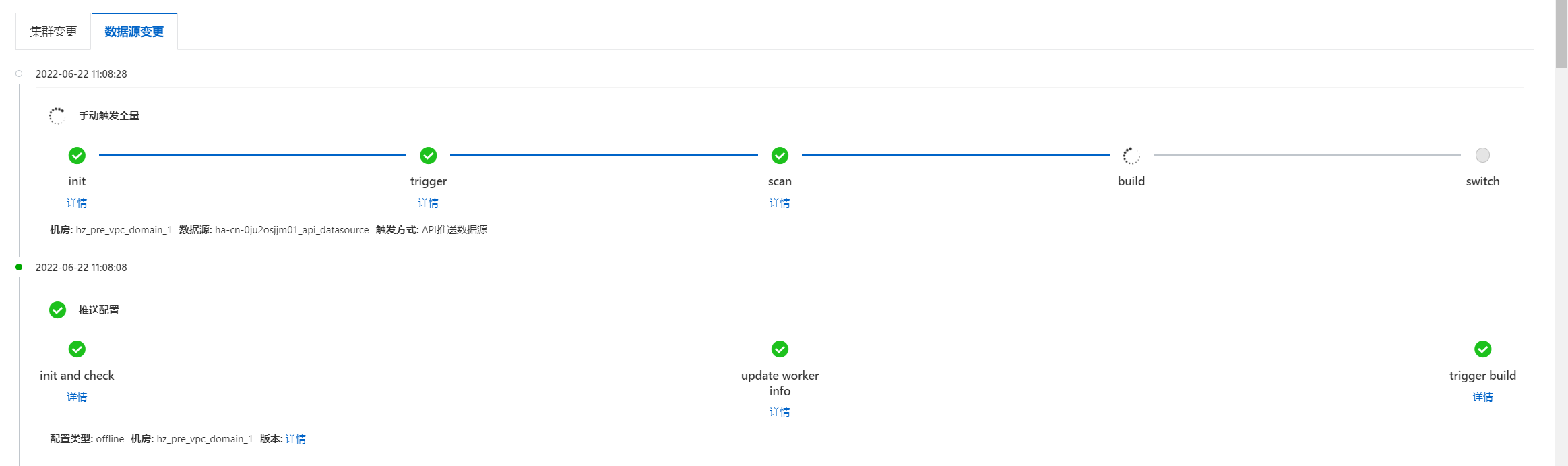
效果測試
語法介紹
query=image_index:'編碼后的需要搜索的文本內容&modal=text&n=10&search_params={}'modal表示模態類型,以文搜圖modal設置為
text,以圖搜圖modal設置為imagen表示指定向量檢索返回的top結果數
文本內容需要經過base64編碼
以文搜圖
在查詢測試頁面通過HA查詢:
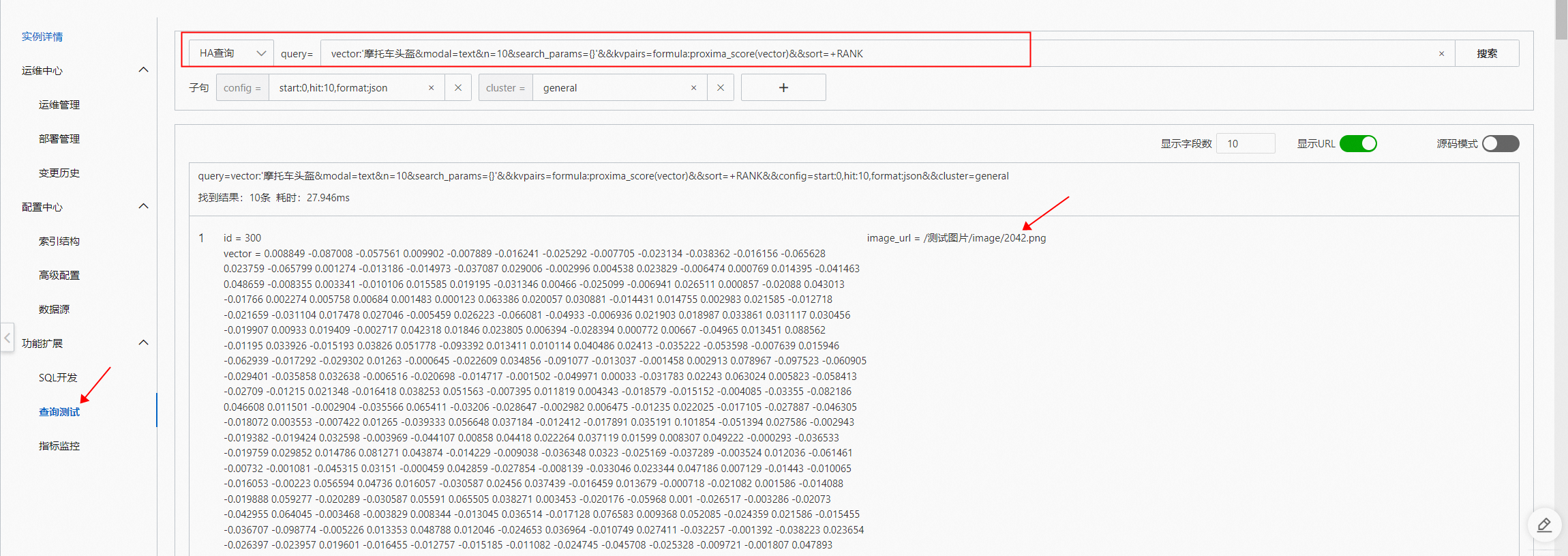
vector:'5pGp5omY6L2mJuWktOeblA==&modal=text&n=10&search_params={}'&&kvpairs=formula:proxima_score(vector)&&sort=+RANK在OSS中查看2042.png 圖片:
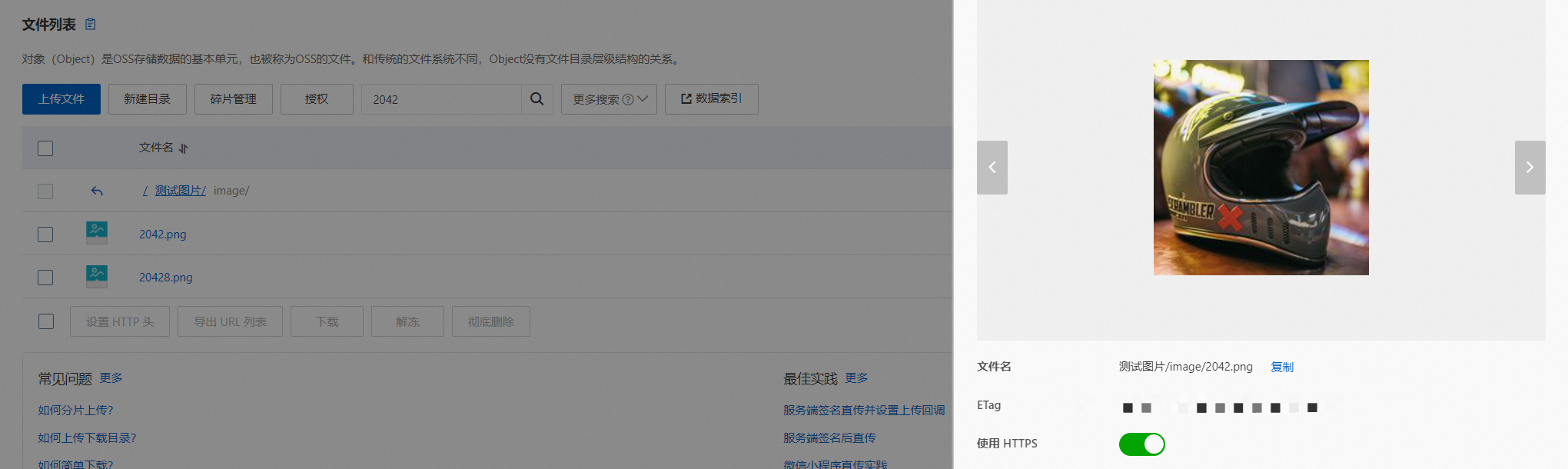
如果搜索的文本內容中特殊字符,需要進行base64編碼,例如搜索內容為“摩托車&頭盔”,則需要進行base64編碼,結果為“5pGp5omY6L2mJuWktOeblA==”
以圖搜圖
由于圖片編碼后長度比較大,暫不支持直接在控制臺查詢測試頁面進行搜索。用戶可以通過SDK進行檢索。
示例:
vector:'base64編碼后的圖片&modal=image&n=10&search_params={}'&&kvpairs=formula:proxima_score(vector)&&sort=+RANKSDK中檢索數據
添加依賴:
pip install alibabacloud-ha3engine搜索 demo:
# -*- coding: utf-8 -*-
from alibabacloud_ha3engine import models, client
from alibabacloud_tea_util import models as util_models
from Tea.exceptions import TeaException, RetryError
def search():
Config = models.Config(
endpoint="參考實例詳情頁>API入口下的API域名",
instance_id="",
protocol="http",
access_user_name="購買實例時設置的用戶名",
access_pass_word="購買實例時設置的密碼"
)
# 如用戶請求時間較長. 可通過此配置增加請求等待時間. 單位 ms
# 此參數可在 search_with_options 方法中使用
runtime = util_models.RuntimeOptions(
connect_timeout=5000,
read_timeout=10000,
autoretry=False,
ignore_ssl=False,
max_idle_conns=50
)
# 初始化 Ha3Engine Client
ha3EngineClient = client.Client(Config)
optionsHeaders = {}
try:
# 示例1: 直接使用 ha 查詢串進行搜索.
# =====================================================
query_str = "config=hit:4,format:json,fetch_summary_type:pk,qrs_chain:search&&query=image_index:'需要搜索的文本內容&modal=text&n=10&search_params={}'&&cluster=general"
haSearchQuery = models.SearchQuery(query=query_str)
haSearchRequestModel = models.SearchRequestModel(optionsHeaders, haSearchQuery)
hastrSearchResponseModel = ha3EngineClient.search(haSearchRequestModel)
print(hastrSearchResponseModel)
except TeaException as e:
print(f"send request with TeaException : {e}")
except RetryError as e:
print(f"send request with Connection Exception : {e}")其他SDK demo可參考開發指南
注意事項
如果對向量檢索耗時有較嚴格的要求,建議向量索引lock內存
存儲圖片路徑或者圖片base64編碼的字段需要設置為STRING
向量索引需要設置為CUSTOMIZED類型
該場景支持HA語法、RESTFUL API,不支持SQL