梯度提升決策樹 (Gradient Boosting Decision Trees) 二分類,是經典的基于梯度提升(Gradient Boosting)的有監督學習模型,可以用來解決二分類問題。
支持計算資源
支持的計算引擎為MaxCompute。
算法簡介
梯度提升決策樹 (Gradient Boosting Decision Trees) 二分類,是經典的基于梯度提升(Gradient Boosting)的有監督學習模型,可以用來解決二分類問題。
算法原理
梯度提升決策樹模型構建了一個由多棵決策樹組成的組合模型。每一棵決策樹對應一個弱學習器,將這些弱學習器組合在一起,可以達到比較好的分類或回歸效果。
梯度提升的基本遞推結構為:
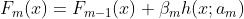
其中,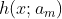 通常為一棵 CART 決策樹,
通常為一棵 CART 決策樹,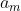 為決策樹的參數,
為決策樹的參數,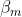 為步長。第m棵決策樹在前m-1棵決策樹的基礎上對目標函數進行優化。最終得到包含若干棵決策樹的模型。
為步長。第m棵決策樹在前m-1棵決策樹的基礎上對目標函數進行優化。最終得到包含若干棵決策樹的模型。
算法使用
該算法實現中包含了XGBoost提出的二階梯度優化目標以及LightGBM的直方圖近似計算。對于一些常見的二分類問題,都可以使用這個算法解決,模型擁有較好的性能,且擁有不錯的可解釋性。
該算法支持稀疏向量格式與多列特征格式的輸入。輸入為稀疏向量格式時,僅能選擇1個String類型的列,每條數據是以單個空格為分隔符的鍵值對,鍵值之間用冒號分隔,例如:1:0.3 3:0.9。輸入為多列特征時,可以選擇多個Double、Bigint和String的列,包括了數值型特征(numerical feature)與類別型特征(categorical feature)。對于數值型特征,算法會對數據進行分箱操作;對于類別型特征,不需要提前進行OneHot預處理,算法會使用 many-vs-many 的分裂策略。
該算法要求二分類的類別必須為0和1。
當該組件與GBDT二分類預測V2組件成對執行完成后,訓練得到的模型支持部署為在線服務,詳細操作可以參考Pipeline部署在線服務。
可視化配置參數
輸入樁配置
輸入樁(從左到右) | 限制數據類型 | 建議上游組件 | 是否必選 |
輸入數據 | 無 | 是 |
組件參數
頁簽 | 參數 | 是否必選 | 描述 | 默認值 |
字段設置 | 是否為稀疏向量格式 | 否 | 輸入表中用于訓練的特征列是否為稀疏向量格式。在稀疏向量格式中,每條數據是以單個空格為分隔符的鍵值對,鍵值之間用冒號分隔,例如: | 否 |
選擇特征列 | 是 | 輸入表中用于訓練的特征列名數組。非稀疏向量格式時,支持類型double/bigint/string;稀疏向量格式時,支持string類型,并且只能選擇1列。 | 無 | |
選擇類別型特征列 | 否 | 非稀疏向量格式,選擇作為類別型特征(categorical feature)處理的列,其他列作為數值型特征處理。 | 無 | |
選擇標簽列 | 是 | 輸入表中用于訓練的標簽列名。 | 無 | |
選擇權重列 | 否 | 輸入表中用于訓練的權重列名。 | 無 | |
參數設置 | 樹的數目 | 否 | 模型中樹的棵數。 | 1 |
最大葉節點數 | 否 | 訓練每棵樹時,最多包含的葉節點個數。 | 32 | |
學習速率 | 否 | 學習率。 | 0.05 | |
訓練樣本比例 | 否 | 訓練每棵樹時,樣本的采樣比例,范圍為 (0, 1]。 | 0.6 | |
訓練特征比例 | 否 | 訓練每棵樹時,特征的采樣比例,范圍為 (0, 1]。 | 0.6 | |
葉節點最少樣本數 | 否 | 訓練每個樹時,各個葉子節點至少包含的樣本數量。 | 500 | |
最大分箱個數 | 否 | 連續特征進行離散分箱時的最大分箱個數。該值越大,進行節點分裂時越精確,但計算代價越大。 | 32 | |
最多類別數 | 否 | 類別型特征最多允許的類別個數:對于一個類別型特征,所有出現的值按頻率從高到低排序后,序位多于該值的類別將合并到一個桶中。該值越大,進行節點分裂時越精確,但也更容易過擬合,計算代價也越大。 | 1024 | |
特征數量 | 否 | 稀疏特征時,填寫最大特征ID+1;不填寫時需要掃描一遍數據計算。 | 根據輸入數據自動計算 | |
全局偏置項 | 否 | 初始預測為正樣本的概率值;不填寫時需要掃描一遍數據進行預估。 | 根據輸入數據自動計算 | |
隨機數產生器種子 | 否 | 隨機種子,用于采樣。 | 0 | |
執行調優 | 底層作業使用的計算資源 | 否 | 底層作業使用的計算資源:
| MaxCompute |
節點數 | 否 | 執行作業的節點數。 | 根據輸入數據自動計算 | |
每節點內存 | 否 | 節點所使用的內存數,單位為MB。 | 根據輸入數據自動計算 | |
線程數 | 否 | 使用多線程加速計算,但成本也更高;一般情況下,隨著線程數的增加,性能會先上升后下降;請謹慎調整線程數。 | 1 |
輸出樁說明
輸出樁 | 存儲位置 | 下游建議組件 | 數據類型 |
模型輸出 | 不需要配置 | MaxCompute表 | |
特征重要性輸出 | 不需要配置 | 無 | MaxCompute表 |
與PS-SMART二分類對比
如果您之前使用PS-SMART二分類訓練組件遇到了一些問題不容易解決,那么可以嘗試使用GBDT二分類V2組件。兩個組件當前的功能和參數支持情況,見下表:
PS-SMART二分類參數 | 對應本組件的參數 |
是否稀疏格式 | 是否為稀疏向量格式 |
選擇特征列 | 選擇特征列 |
選擇標簽列 | 選擇標簽列 |
選擇權重列 | 選擇權重列 |
評估指標類型 | 不適用,默認為 AUC 指標,可以在 worker 日志中查看。 |
樹數量 | 樹的數目 |
樹最大深度 | 最大葉節點數:換算公式為: |
數據采樣比例 | 訓練樣本比例 |
特征采樣比例 | 訓練特征比例 |
L1懲罰項系數 | 暫不支持。 |
L2懲罰項系數 | 暫不支持。 |
學習速率 | 學習速率 |
近似Sketch精度 | 最大分箱個數:換算公式為: |
最小分裂損失變化 | 葉節點最少樣本數:兩者不能直接換算,但都可用于控制過擬合。 |
特征數量 | 特征數量 |
全局偏置項 | 全局偏置項 |
隨機數產生器種子 | 隨機數產生器種子 |
特征重要性類型 | 不適用,當前默認為信息增益。 |
計算核心數 | 節點數:不能直接使用相同數值,推薦先試用系統自動分配,然后進行細調。 |
每個核內存大小 | 每節點內存:不能直接使用相同數值,推薦先試用系統自動分配,然后進行細調。 |